I started this as a response to Keith Murphy’s post at http://www.paragon-cs.com/wordpress/?p=54, but it got long, so it deserves its own post. The basic context is figuring out how not to cause duplicate information if a large INSERT statement fails before finishing.
Firstly, the surefire way to make sure there are no duplicates if you have a unique (or primary) key is to use INSERT IGNORE INTO.
Secondly, I just experimented with adding an index to an InnoDB table that had 1 million rows, and here’s what I got (please note, this is one experience only, the plural of “anecdote” is *not* “data”; also I did this in this particular order, so there may have been caching taking place):
Way #1:
– ALTER the table to add the new index. This was the slowest method, taking over 13 minutes.
Way #2:
– CREATE a new table with the same schema as the old except for adding the new index
– INSERT INTO newtable SELECT * FROM oldtable;
– ALTER TABLE oldtable RENAME somethingdifferent;
– ALTER TABLE newtable RENAME oldtable;
The ALTER TABLEs happen instantly. This was faster by a few seconds, which is statistically negligible given the 13+ minutes total time.
Way #3:
– mysqldump the table schema only (–no-data) into a file (tableschema.sql).
– mysqldump the table data only (-t) into another file (tabledata.sql).
– optionally pipe into awk to replace “^INSERT INTO” with “INSERT IGNORE INTO”
– edit the table schema file, adding the new index into the table definition
– optionally change the name of the table to something like newtable, making sure to change the DROP TABLE *and* CREATE TABLE statements.
– mysql < tableschema.sql (this will drop the old table unless you changed the name)
- mysql < tabledata.sql ()
- If you changed the table name in the DROP and CREATE statements, run - ALTER TABLE oldtable RENAME somethingdifferent; and ALTER TABLE newtable RENAME oldtable;
- Delete the "somethingdifferent" table
This way took just over 10 minutes, 3 minutes faster than the other 2 ways, for a time savings of 25%.
CAVEAT: MySQL helpfully moves references on a table to the new table name when you ALTER TABLE...RENAME. You will have to adjust your foreign keys, stored procedures, functions and triggers if you use anything other than Way #1.
CAVEAT #2: Make sure that the character set of the MySQL server is supported by the MySQL client and the operating system where you're dumping the file to, otherwise special characters can end up falling victim to mojibake.
I started this as a response to Keith Murphy’s post at http://www.paragon-cs.com/wordpress/?p=54, but it got long, so it deserves its own post. The basic context is figuring out how not to cause duplicate information if a large INSERT statement fails before finishing.
Firstly, the surefire way to make sure there are no duplicates if you have a unique (or primary) key is to use INSERT IGNORE INTO.
Secondly, I just experimented with adding an index to an InnoDB table that had 1 million rows, and here’s what I got (please note, this is one experience only, the plural of “anecdote” is *not* “data”; also I did this in this particular order, so there may have been caching taking place):
Way #1:
– ALTER the table to add the new index. This was the slowest method, taking over 13 minutes.
Way #2:
– CREATE a new table with the same schema as the old except for adding the new index
– INSERT INTO newtable SELECT * FROM oldtable;
– ALTER TABLE oldtable RENAME somethingdifferent;
– ALTER TABLE newtable RENAME oldtable;
The ALTER TABLEs happen instantly. This was faster by a few seconds, which is statistically negligible given the 13+ minutes total time.
Way #3:
– mysqldump the table schema only (–no-data) into a file (tableschema.sql).
– mysqldump the table data only (-t) into another file (tabledata.sql).
– optionally pipe into awk to replace “^INSERT INTO” with “INSERT IGNORE INTO”
– edit the table schema file, adding the new index into the table definition
– optionally change the name of the table to something like newtable, making sure to change the DROP TABLE *and* CREATE TABLE statements.
– mysql < tableschema.sql (this will drop the old table unless you changed the name)
- mysql < tabledata.sql ()
- If you changed the table name in the DROP and CREATE statements, run - ALTER TABLE oldtable RENAME somethingdifferent; and ALTER TABLE newtable RENAME oldtable;
- Delete the "somethingdifferent" table
This way took just over 10 minutes, 3 minutes faster than the other 2 ways, for a time savings of 25%.
CAVEAT: MySQL helpfully moves references on a table to the new table name when you ALTER TABLE...RENAME. You will have to adjust your foreign keys, stored procedures, functions and triggers if you use anything other than Way #1.
CAVEAT #2: Make sure that the character set of the MySQL server is supported by the MySQL client and the operating system where you're dumping the file to, otherwise special characters can end up falling victim to mojibake.
While researching an article I came across a piece at http://www.simple-talk.com/sql/t-sql-programming/cursors-and-embedded-sql/. Basically the author says “embedded SQL” is bad — meaning developers should never put SQL in their code. Nor should they use ORM tools to generate SQL for them.
Instead, they should access everything they need through stored procedures. I have mixed feelings about this. On one hand, you have to give table-access permissions to users and then deal with the resulting security risks sounds very control-freakish to me. On the other hand, I agree that embedded code can be bad because if you change the database model in any way, you have to rewrite the procedural code that relies on the existence of the previous model.
And of course, stored procedures also help make your code more modular. But this article basically advocates that database administrators really need to do a lot of heavy coding into the database.
(The title of this post is just something that came to me when I read the article, because the author’s opinions were sparked by a cursor gone bad. (cursors gone wild?) )
While researching an article I came across a piece at http://www.simple-talk.com/sql/t-sql-programming/cursors-and-embedded-sql/. Basically the author says “embedded SQL” is bad — meaning developers should never put SQL in their code. Nor should they use ORM tools to generate SQL for them.
Instead, they should access everything they need through stored procedures. I have mixed feelings about this. On one hand, you have to give table-access permissions to users and then deal with the resulting security risks sounds very control-freakish to me. On the other hand, I agree that embedded code can be bad because if you change the database model in any way, you have to rewrite the procedural code that relies on the existence of the previous model.
And of course, stored procedures also help make your code more modular. But this article basically advocates that database administrators really need to do a lot of heavy coding into the database.
(The title of this post is just something that came to me when I read the article, because the author’s opinions were sparked by a cursor gone bad. (cursors gone wild?) )
So, O’Reilly’s ONLamp.com has published the “Top 10 MySQL Best Practices” at http://www.onlamp.com/pub/a/onlamp/2002/07/11/MySQLtips.html. Sadly, I find most “best practice” list do not thoroughly explain the “why” enough so that people can make their own decisions.
For instance, #3 is “Protect the MySQL installation directory from access by other users.” I was intrigued at what they would consider the “installation” directory. By reading the tip, they actually mean the data directory. They say nothing of the log directory, nor that innodb data files may be in different places than the standard myisam data directories.
They perpetuate a myth in #4, “Don’t store binary data in MySQL.” What they really mean is “don’t store large data in MySQL”, which they go into in the tip. While it’s true that there is very little benefit to having binary data in a database, they don’t go into what those benefits are. This means that people can’t make informed decisions, just “the best practice is this so I’m doing it.”
The benefit of putting binary data in MySQL is to be able to associate metadata and other data. For instance, “user 200 owns file 483”. If user 200 is gone from the system, how can you make sure file 483 is as well? There’s no referential integrity unless it’s in the database. While it’s true that in most cases people would rather sacrifice the referential integrity for things like faster database backups and easier partitioning of large data objects, I believe in giving people full disclosure so they can make their own informed decision.
#5 is my biggest pet peeve. “Stick to ANSI SQL,” with the goal being to be able to migrate to a different platform without having to rewrite the code. Does anyone tell Oracle folks not to use pl/sql like collections? Nobody says “SQL is a declarative language, pl/sql is procedural therefore you should never use it”. How about SQL Server folks not to use transact-sql statements like WAITFOR? MATCH… AGAINST is not standard SQL, so I should never use it?
Now, of course, if you’re selling a product to be run on different database platforms, then sure, you want to be platform agnostic. But you’d know that from the start. And if you have to migrate platforms you’re going to have to do lots of work anyway, because there are third-party additions to all the software any way.
And why would *anyone* choose a specific database, and then *not* use those features? I think that it’s a good tip to stick to ANSI SQL if you *know* you want to, or if you have no idea about the DBMS you’re using.
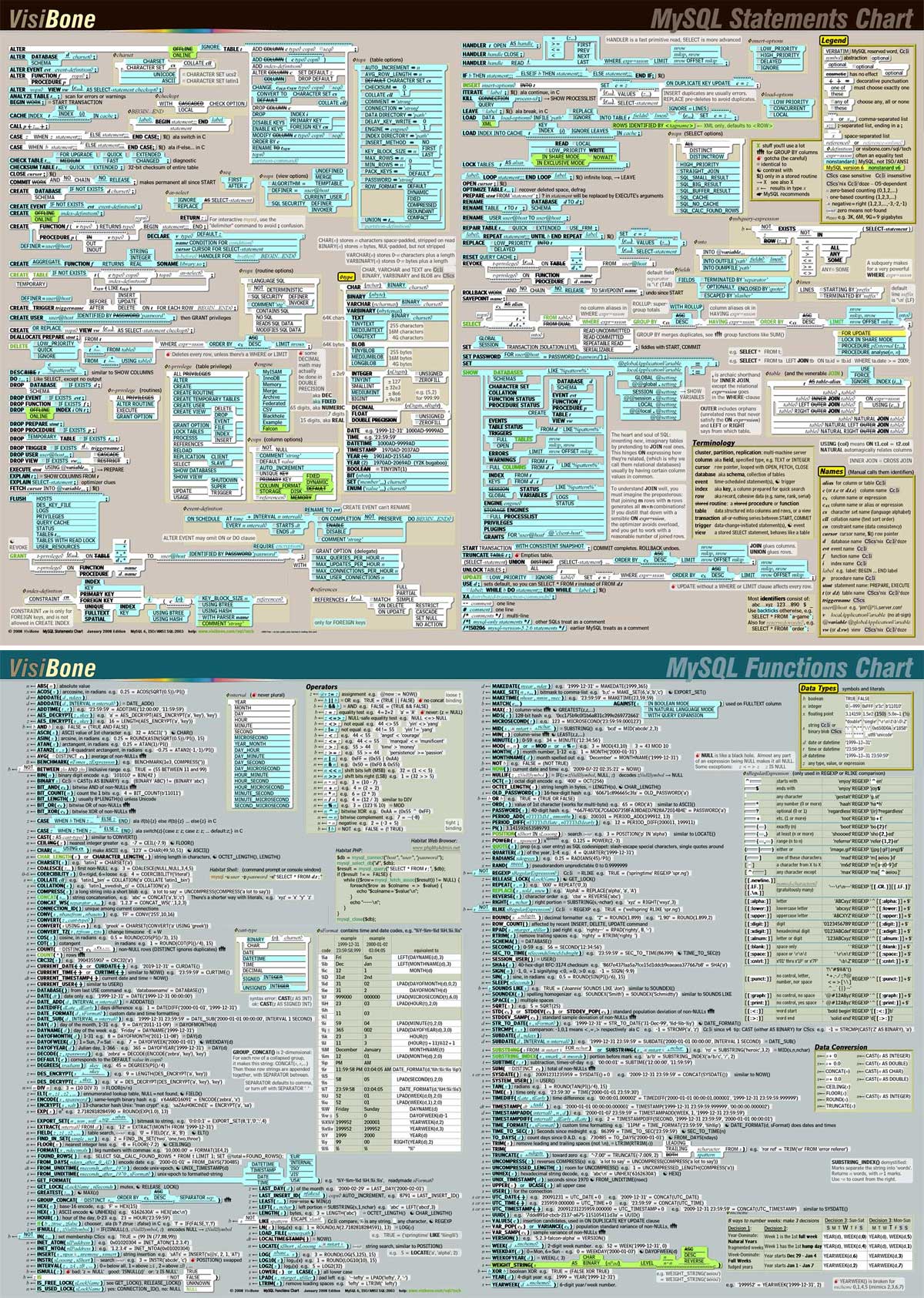
If you want to see how this cripples MySQL, check out Visibone’s SQL chart at: http://www.visibone.com/sql/chart_1200.jpg — you can buy it here: http://sheeri.com/archives/104. I may post later on about my own personal MySQL Best Practices….
So, O’Reilly’s ONLamp.com has published the “Top 10 MySQL Best Practices” at http://www.onlamp.com/pub/a/onlamp/2002/07/11/MySQLtips.html. Sadly, I find most “best practice” list do not thoroughly explain the “why” enough so that people can make their own decisions.
For instance, #3 is “Protect the MySQL installation directory from access by other users.” I was intrigued at what they would consider the “installation” directory. By reading the tip, they actually mean the data directory. They say nothing of the log directory, nor that innodb data files may be in different places than the standard myisam data directories.
They perpetuate a myth in #4, “Don’t store binary data in MySQL.” What they really mean is “don’t store large data in MySQL”, which they go into in the tip. While it’s true that there is very little benefit to having binary data in a database, they don’t go into what those benefits are. This means that people can’t make informed decisions, just “the best practice is this so I’m doing it.”
The benefit of putting binary data in MySQL is to be able to associate metadata and other data. For instance, “user 200 owns file 483”. If user 200 is gone from the system, how can you make sure file 483 is as well? There’s no referential integrity unless it’s in the database. While it’s true that in most cases people would rather sacrifice the referential integrity for things like faster database backups and easier partitioning of large data objects, I believe in giving people full disclosure so they can make their own informed decision.
#5 is my biggest pet peeve. “Stick to ANSI SQL,” with the goal being to be able to migrate to a different platform without having to rewrite the code. Does anyone tell Oracle folks not to use pl/sql like collections? Nobody says “SQL is a declarative language, pl/sql is procedural therefore you should never use it”. How about SQL Server folks not to use transact-sql statements like WAITFOR? MATCH… AGAINST is not standard SQL, so I should never use it?
Now, of course, if you’re selling a product to be run on different database platforms, then sure, you want to be platform agnostic. But you’d know that from the start. And if you have to migrate platforms you’re going to have to do lots of work anyway, because there are third-party additions to all the software any way.
And why would *anyone* choose a specific database, and then *not* use those features? I think that it’s a good tip to stick to ANSI SQL if you *know* you want to, or if you have no idea about the DBMS you’re using.
If you want to see how this cripples MySQL, check out Visibone’s SQL chart at: http://www.visibone.com/sql/chart_1200.jpg — you can buy it here: http://sheeri.com/archives/104. I may post later on about my own personal MySQL Best Practices….
So, the article at:
http://mysql-dba-journey.blogspot.com/2007/11/mysql-and-vmware.html says:
Don’t get seduced to the dark side unless you understand all the issues.
And that’s wonderful and all, but….what are all the issues? What are some of the issues? Is it related more to VMware, or more to MySQL, or more to MySQL on VMware? Is it something like “VMware isn’t stable” or more like “load testing on vmware isn’t always going to work because you won’t have full resources”?
Many people talk about using virtualization for development and testing….but if you develop and test on a virtual machine and then put it on a physical machine for production, isn’t that basically having differing environments for dev/testing and production, which is usually seen as bad? If a line of code crashes a virtual machine but is fine on production, is it worth tracking the bug down? How many hours will you spend doing that?
Also, how is using a virtual machine better/worse/different from using something like mysqld_multi on a machine with many IPs, or other strategies folks use in dev/test so they don’t have to buy the exact same hardware as in production, but still have the same separation of databases, etc?
So, the article at:
http://mysql-dba-journey.blogspot.com/2007/11/mysql-and-vmware.html says:
Don’t get seduced to the dark side unless you understand all the issues.
And that’s wonderful and all, but….what are all the issues? What are some of the issues? Is it related more to VMware, or more to MySQL, or more to MySQL on VMware? Is it something like “VMware isn’t stable” or more like “load testing on vmware isn’t always going to work because you won’t have full resources”?
Many people talk about using virtualization for development and testing….but if you develop and test on a virtual machine and then put it on a physical machine for production, isn’t that basically having differing environments for dev/testing and production, which is usually seen as bad? If a line of code crashes a virtual machine but is fine on production, is it worth tracking the bug down? How many hours will you spend doing that?
Also, how is using a virtual machine better/worse/different from using something like mysqld_multi on a machine with many IPs, or other strategies folks use in dev/test so they don’t have to buy the exact same hardware as in production, but still have the same separation of databases, etc?
Peter makes an interesting post about the MySQL company’s trademarks at http://www.mysqlperformanceblog.com/2007/10/26/mysql-support-or-support-for-mysql-mysql-trademark-policies/
The point is that Peter is not selling “MySQL Support” — he is selling “Support *for* MySQL”. “MySQL Support” is the name of a product that MySQL offers. Even if some other consulting company used the name before the MySQL company ever did, MySQL still has the rights to the name.
I chose to name my podcast “OurSQL: The MySQL Database Podcast for the Community, By the Community.” I chose every word carefully. For instance, I call it “the MySQL Database Podcast” so that anyone looking for a podcast about “database” will find it.
I could have just called it “MySQL Podcast”. But if the company MySQL (AB or Inc) ever makes a podcast, they would do the same thing to me that they do to you. I have to distinguish it’s “a podcast about MySQL”, not “MySQL’s podcast”. In fact if you look for “oursql” references, there is actually software released in September 2001 called “oursql”, but it was only released once and I have only ever found a handful of e-mails about it.
Similarly with “Technocation, Inc”. I googled around for it and found that a Baltimore, MD USA paper has a column called “technocation”, and it’s similar to why I picked the name — technology + education. But there’s no way anyone would confuse the two.
Same thing as MySQL would do if they made their own toolkit. “MySQL Toolkit” is in fact a really bad name because it’s so generic. Right now there’s no confusion, because MySQL doesn’t have a toolkit. Same with the “MySQL Magazine”. If MySQL ever puts out a magazine, they’ll send a letter right away. I was actually worried that “The MySQL Guy Podcast” at http://www.themysqlguy.com/ would get a letter from them. After all, there are plenty of “MySQL guys” out there, and he doesn’t work for the company……(hence why I’m the “She-BA”, not “MySQL Gal”).
In fact, Microsoft seems to do this on purpose. They named their database engine “SQL Server”. I’ve been frustrated when I get Microsoft pages when I’m just looking for “something relating to SQL”. I’d much rather get something related to the SQL standard. Same with their “Windows Mobile” platform. Check out their list of servers on the right-hand side of the page at http://www.microsoft.com/servers/default.mspx — if you’re looking for “security” on a Windows server, chances are most of your search result will be for the “Security Server” that Microsoft offers. Ditto with “Content Management Server” and “Data Protection Manager” and “Speech Server” and “Virtual Server” and “Small Business Server”…etc.
If you have questions about Intellectual Property (IP) or Patents in the United States, I highly recommend retaining services from the law firm of Bakos and Kritzer — http://www.bakoskritzer.com/. It’s not just a law firm where my brother is a partner, it’s also a damn good one.
(Speaking of name, I will likely be changing my name in the near future to “Sheeri K. Cabral”, so if you see it around, don’t get confused. You can always find me at www.sheeri.com )
Peter makes an interesting post about the MySQL company’s trademarks at http://www.mysqlperformanceblog.com/2007/10/26/mysql-support-or-support-for-mysql-mysql-trademark-policies/
The point is that Peter is not selling “MySQL Support” — he is selling “Support *for* MySQL”. “MySQL Support” is the name of a product that MySQL offers. Even if some other consulting company used the name before the MySQL company ever did, MySQL still has the rights to the name.
I chose to name my podcast “OurSQL: The MySQL Database Podcast for the Community, By the Community.” I chose every word carefully. For instance, I call it “the MySQL Database Podcast” so that anyone looking for a podcast about “database” will find it.
I could have just called it “MySQL Podcast”. But if the company MySQL (AB or Inc) ever makes a podcast, they would do the same thing to me that they do to you. I have to distinguish it’s “a podcast about MySQL”, not “MySQL’s podcast”. In fact if you look for “oursql” references, there is actually software released in September 2001 called “oursql”, but it was only released once and I have only ever found a handful of e-mails about it.
Similarly with “Technocation, Inc”. I googled around for it and found that a Baltimore, MD USA paper has a column called “technocation”, and it’s similar to why I picked the name — technology + education. But there’s no way anyone would confuse the two.
Same thing as MySQL would do if they made their own toolkit. “MySQL Toolkit” is in fact a really bad name because it’s so generic. Right now there’s no confusion, because MySQL doesn’t have a toolkit. Same with the “MySQL Magazine”. If MySQL ever puts out a magazine, they’ll send a letter right away. I was actually worried that “The MySQL Guy Podcast” at http://www.themysqlguy.com/ would get a letter from them. After all, there are plenty of “MySQL guys” out there, and he doesn’t work for the company……(hence why I’m the “She-BA”, not “MySQL Gal”).
In fact, Microsoft seems to do this on purpose. They named their database engine “SQL Server”. I’ve been frustrated when I get Microsoft pages when I’m just looking for “something relating to SQL”. I’d much rather get something related to the SQL standard. Same with their “Windows Mobile” platform. Check out their list of servers on the right-hand side of the page at http://www.microsoft.com/servers/default.mspx — if you’re looking for “security” on a Windows server, chances are most of your search result will be for the “Security Server” that Microsoft offers. Ditto with “Content Management Server” and “Data Protection Manager” and “Speech Server” and “Virtual Server” and “Small Business Server”…etc.
If you have questions about Intellectual Property (IP) or Patents in the United States, I highly recommend retaining services from the law firm of Bakos and Kritzer — http://www.bakoskritzer.com/. It’s not just a law firm where my brother is a partner, it’s also a damn good one.
(Speaking of name, I will likely be changing my name in the near future to “Sheeri K. Cabral”, so if you see it around, don’t get confused. You can always find me at www.sheeri.com )
Does anyone have any ways they create an API for their stored routines (functions and procedures)? Currently it seems as though I have to parse the CREATE statement to get the input variables….Has anyone else done this? Is it in any third party tools?
Does anyone have any ways they create an API for their stored routines (functions and procedures)? Currently it seems as though I have to parse the CREATE statement to get the input variables….Has anyone else done this? Is it in any third party tools?
So, at midnight I got a call from customer service saying our site was slow. I narrowed it down to one of our auxiliary databases, that seems to have gotten wedged just about midnight. Normal queries that took less than 4 seconds started taking longer and longer, moving up to 5 seconds and past 30 seconds in the span of a minute or so.
In the moment, I thought killing off all the queries would be a good move. My kill script, which consists of:
for i in `/usr/bin/mysql -u user -pPass -e 'show full processlist' | grep appuser | cut -f1`
do
mysql -u user -pPass -e "kill $i"
done
This will attempt to kill any mysql connection owned by the appuser. I used it a few times, and it didn’t work. So I used a trick I learned when we bring our site down — sometimes there are straggling connections to mysql, so what I do is change the app user’s password by direct manipulation of the mysql.user table and flush privileges.
Within 10 seconds, all the connections from the appuser were gone, and when I put the correct password back and flushed privileges, everything came back normal. Queries started taking their usual amount of time.
Why is it that queries that refused to be killed by “kill”, and yet changing the password for the user they were running as killed them off? Some were running more than 45 seconds, in various states of “Sending data” and “closing tables”. Nothing was running for much longer than 60 seconds, so it doesn’t seem like there was a big query that was wedging things.
Oh, and what happened at midnight to cause this? No clue, the only thing we run at that time is a PURGE LOGS FROM MASTER, which we do every hour, as we fill up a 1.1G binary log file every 20 minutes or so. This database holds a particularly heavy write application and also runs reports, so we optimize the tables every week (wednesday at 2 am). I’ve put the optimization to daily, as when I ran it manually this morning it took about 20 seconds.
Anyone have an idea about why changing the password worked so quickly when kill did not?
So, at midnight I got a call from customer service saying our site was slow. I narrowed it down to one of our auxiliary databases, that seems to have gotten wedged just about midnight. Normal queries that took less than 4 seconds started taking longer and longer, moving up to 5 seconds and past 30 seconds in the span of a minute or so.
In the moment, I thought killing off all the queries would be a good move. My kill script, which consists of:
for i in `/usr/bin/mysql -u user -pPass -e 'show full processlist' | grep appuser | cut -f1`
do
mysql -u user -pPass -e "kill $i"
done
This will attempt to kill any mysql connection owned by the appuser. I used it a few times, and it didn’t work. So I used a trick I learned when we bring our site down — sometimes there are straggling connections to mysql, so what I do is change the app user’s password by direct manipulation of the mysql.user table and flush privileges.
Within 10 seconds, all the connections from the appuser were gone, and when I put the correct password back and flushed privileges, everything came back normal. Queries started taking their usual amount of time.
Why is it that queries that refused to be killed by “kill”, and yet changing the password for the user they were running as killed them off? Some were running more than 45 seconds, in various states of “Sending data” and “closing tables”. Nothing was running for much longer than 60 seconds, so it doesn’t seem like there was a big query that was wedging things.
Oh, and what happened at midnight to cause this? No clue, the only thing we run at that time is a PURGE LOGS FROM MASTER, which we do every hour, as we fill up a 1.1G binary log file every 20 minutes or so. This database holds a particularly heavy write application and also runs reports, so we optimize the tables every week (wednesday at 2 am). I’ve put the optimization to daily, as when I ran it manually this morning it took about 20 seconds.
Anyone have an idea about why changing the password worked so quickly when kill did not?
aka…..”when good queries go bad!”
So, today the developers were debugging why a script was running much longer than expected. They were doing text database inserts, and got to the point where they realized that double the amount of text meant the queries took double the amount of time.
You see, they were doing similar text inserts over and over, instead of using connection pooling and/or batching them. Apparently the other DBA explained that it was a limitation of MySQL, but either the developers didn’t convey what they were doing well, or the DBA didn’t think to mention batching.
I ran a simple test on a test server. I used the commandline to connect to a db server on the same machine (even though in qa and production the db machine is on a different machine) just to make a point:
| Type |
Connects |
Queries |
Queries per connect
Length of data transmitted |
Time |
| One-off |
1000 |
1 |
619 bytes |
12.232s |
| Single Connection |
1 |
1000 |
604 kilobytes |
0.268s |
| Batch |
1 |
1 |
517 kilobytes |
0.135s |
So 1000 INSERTs using 1 connection is over 45 times faster than 1000 INSERTs using 1000 connections.
Using 1 batch INSERT statement is over 1.75 times faster than using 1 connection.
Using 1 batch INSERT statement is over 90 times faster than 1000 INSERTs using 1000 connections.
Note that while it’s faster to send a batch, if you don’t support sending 517 kilobytes to your database at once, you’ll want to break it up. That’s a small coding price to pay for 90x the database performance!!!
For reference, the formats used:
One-off:
INSERT INTO foo (col1, col2…) VALUES (val1, val2…);
Single Connection:
INSERT INTO foo (col1, col2…) VALUES (val1, val2…);
INSERT INTO foo (col1, col2…) VALUES (val1a, val2a…);
Batch: INSERT INTO foo (col1, col2…) VALUES (val1, val2…), (val1a, val2a);
aka…..”when good queries go bad!”
So, today the developers were debugging why a script was running much longer than expected. They were doing text database inserts, and got to the point where they realized that double the amount of text meant the queries took double the amount of time.
You see, they were doing similar text inserts over and over, instead of using connection pooling and/or batching them. Apparently the other DBA explained that it was a limitation of MySQL, but either the developers didn’t convey what they were doing well, or the DBA didn’t think to mention batching.
I ran a simple test on a test server. I used the commandline to connect to a db server on the same machine (even though in qa and production the db machine is on a different machine) just to make a point:
| Type |
Connects |
Queries |
Queries per connect
Length of data transmitted |
Time |
| One-off |
1000 |
1 |
619 bytes |
12.232s |
| Single Connection |
1 |
1000 |
604 kilobytes |
0.268s |
| Batch |
1 |
1 |
517 kilobytes |
0.135s |
So 1000 INSERTs using 1 connection is over 45 times faster than 1000 INSERTs using 1000 connections.
Using 1 batch INSERT statement is over 1.75 times faster than using 1 connection.
Using 1 batch INSERT statement is over 90 times faster than 1000 INSERTs using 1000 connections.
Note that while it’s faster to send a batch, if you don’t support sending 517 kilobytes to your database at once, you’ll want to break it up. That’s a small coding price to pay for 90x the database performance!!!
For reference, the formats used:
One-off:
INSERT INTO foo (col1, col2…) VALUES (val1, val2…);
Single Connection:
INSERT INTO foo (col1, col2…) VALUES (val1, val2…);
INSERT INTO foo (col1, col2…) VALUES (val1a, val2a…);
Batch: INSERT INTO foo (col1, col2…) VALUES (val1, val2…), (val1a, val2a);
Skoll is a Community-Based Testing project out of the University of Maryland. Their first testing framework comes for MySQL. Watch Sandro Fouché, graduate researcher on this project, take you through what Skoll is, how it’s beneficial, and how you can use it with an actual demo. The Skoll testing client for MySQL can be downloaded here:
http://www.cs.umd.edu/projects/skoll/contribute/
The video can be played or downloaded using the “play” or “download” link from the original article at http://www.technocation.org.
Skoll is a Community-Based Testing project out of the University of Maryland. Their first testing framework comes for MySQL. Watch Sandro Fouché, graduate researcher on this project, take you through what Skoll is, how it’s beneficial, and how you can use it with an actual demo. The Skoll testing client for MySQL can be downloaded here:
http://www.cs.umd.edu/projects/skoll/contribute/
The video can be played or downloaded using the “play” or “download” link from the original article at http://www.technocation.org.
Since I know a lot of MySQLers use Perl, I wanted to pass this along. Today was the first I’d heard of this survey, so I’m thinking that there are a lot of other folks who use Perl occasionally as I do (or even regularly) that are in the dark. Apparently it began in late July, and announced at OSCON 2007, so I apologize if you’ve heard about it over and over.
Take the survey now, as you only have until September 30th to do so!
http://perlsurvey.org/
Since I know a lot of MySQLers use Perl, I wanted to pass this along. Today was the first I’d heard of this survey, so I’m thinking that there are a lot of other folks who use Perl occasionally as I do (or even regularly) that are in the dark. Apparently it began in late July, and announced at OSCON 2007, so I apologize if you’ve heard about it over and over.
Take the survey now, as you only have until September 30th to do so!
http://perlsurvey.org/
{kind=link}