This is the 182nd edition of Log Buffer, the weekly review of database blogs. Make sure to read the whole edition so you do not miss where to submit your SQL limerick!
This week started out with me posting about International Women’s Day, and has me personally attending Confoo (Montreal) which is an excellent conference I hope to return to next year. I learned a lot from confoo, especially the blending nosql and sql session I attended.
This week was also the Hotsos Symposium. Doug’s Oracle Blog has a series of posts about Hotsos. If all this talk about conferences has gotten you excited, Joshua Drake notes that 14 days and the hotel is almost full for postgresql conference east which is March 25th-28th in Philadelphia. And the Oracle database insider notes that the Oracle OpenWorld call for papers is now open.
According to Susan Visser this week (ending tomorrow) is also read an e-book week. So if you have not already done so, read an e-book! She links a coupon for an e-book in the post.
Craig Mullins notes that the mainframe is a good career choice in Mainframes: The Safe IT Career Choice. He notes that the mainframe is still not dead:
People having been predicting the death of the mainframe since the advent of client/server in the late 1980s. That is more than 20 years! Think of all the things that have died in that timespan while the mainframe keeps on chugging away: IBM’s PC business, Circuit City, Koogle peanut butter, public pay phones, Johnny Cash… the list is endless.
In other career-related news, Antonio Cangiano is looking for [2] top-notch student hackers for a 16-month internship at IBM in Toronto starting in May. All the details, including how to apply, are in Cangiano’s blog post.
Willie Favero wants to know how you “solve the batch dilemma” for issues like “shrinking your batch window, designing your batch to play nicely with … OLTP” in how’s your batch workload doing? Perhaps Favero should read the updated batch best practices posted by Anthony Shorten.
Bryan Smith surveys a more personal question by asking if you go both ways and “manage both DB2 for Linux, UNIX, and Windows and DB2 for z/OS” in don’t ask, don’t tell, bi-platform DBAs. This week’s Log Buffer editor admits to being a tri-platform DBA — she has tried many platforms, and in fact, many databases (MySQL, Oracle, DB2, SQL Server, Sybase, Postgres and Ingres)!
Hari Prasanna Srinivasan promotes a patching survey in Oracle really wants to hear from you! Patching Survey.
Henrik Loeser explains what a deadlock and a hot spot are by using a real life analogy taken from a police report in deadlock and hot spot in real life.
Jamie Thomson asks why do you abbreviate schema names?. Shlomi Noach tries to solve the issue that “there is no consistent convention as for how to write [about table aliases in] an SQL query” in proper sql table alias use conventions. Noach also gives us a tip: faster than truncate.
Leons Petrazickis reminds us that “rulesets are chains” and it is important to have your rulesets in the proper order in iptables firewall pitfall.
Anyone interested in the history of MySQL AB will be informed after reading Dries Buytaert’s article.
Gavin Towey shares his software that helps centrally manage 120 MySQL servers in qsh.pl: distributed query tool For those who want to learn more about column-oriented databases, particularly in MySQL, Robin Schumacher of the InfiniDB blog announces that there is a MySQL University session recording on MySQL column databases now available. MySQL join-fu expert Jay Pipes has moved his blog to www.joinfu.com and starts with An SQL Puzzle and of course a follow up on the sql puzzle.
Ivan Zoratti is happy that finally, slides posted for the MySQL DW breakfast. Venu Anuganti gives you tips on one of the most common MySQL frustrations: optimizing subqueries in how to improve subqueries derived tables performance. Justin Swanhart posts the way in which he Gets Linux performance information from your MySQL database without shell access and emulates a ‘top’ CPU summary using /proc/stat and MySQL using the same method.
The Oracle Apps blog has an introduction to Oracle user productivity kit (UPK). Even though in this editor’s opinion the article is very sales-pitchy, it has valuable information, and does indeed live up to its promise:
UPK is a software tool that can capture all the steps in a system process. It records every keystroke, every click of the mouse, each menu option chosen and each button pressed. All this is done in the UPK Recorder by going through the transaction and pressing “printscreen” after every user action. From this, without any further effort from the developer, UPK builds a number of valuable outputs.
Allen White gives a great tip on how to optimize queries in keep your data clean.
Mike Dietrich reminds you to remove “old” parameters and events from your init.ora when upgrading, “as keeping them will definitely slow down the database performance in the new release.” He shows evidence of slowness when this is not done. Dietrich also shows how you can be gathering workload statistics “to give the optimizer some good knowledge about how powerful your IO-system might be”, especially “a few days after upgrading to the new release…while a real workload is running.”
Brian Aker shows the exciting features coming soon in Drizzle in Drizzle, Cherry, Roadmap for our Next Release.
Maybe you are thinking of migrating, not upgrading…..The O’Reilly Radar shows how to asses an Oracle to MySQL migration in MySQL migration and risk management. Actually, that article interviews Ronald Bradford on the subject — Bradford has been prolific lately, updating free my.cnf advice series and “Don’t Assume”: MySQL for the Oracle DBA series. Nick Quarmby also talks about migrating Oracle, but not to a new database, just to a new platform, in his primer on migrating Oracle Applications to new platforms. And the big news comes from Carlos of dataprix that Twitter will migrate from MySQL to Cassandra DB.
Paul S. Randal explains his way of benchmarking: 1 Tb table population on SQL Server.
Pete Finnigan shares his slides from a webinar on how to secure oracle, and Denis Pilipchuk shares his approaches for discovering security vulnerabilities in software applications.
Jeff Davis shares his thoughts about scalability and the relational model. Robert Treat responds actually, the relational model doesn’t scale and Baron Schwartz counters with NoSQL doesn’t mean non-relational.
Buck Woody explains “whenever you want to know something about SQL Server’s configuration, whether that’s the Instance itself or a database, you have a few options” — and of course what those options are — in system variables, stored procedures or functions for meta data.
This week’s T-SQL Tuesday topic was I/O. There are many links to great blog posts in the comments; three random posts I chose to highlight: Michael Zilberstein talks about IO capacity planning, while Kalen Delaney talks about using STATISTICS IO in I/O, you know, and Merrill Aldrich chimes in with information on real world SSD’s. Aldrich also begs folks not to waste resources and make more work for developers and DBAs in dear ISV, you’re keeping me awake nights with your VARCHAR() dates.
And we end with a bit of fin: Paul Nielsen wants us all to have a bit of fun; he has posted an SQL limerick and asks readers to create there own in there once was in Dublin a query.
This is the 182nd edition of Log Buffer, the weekly review of database blogs. Make sure to read the whole edition so you do not miss where to submit your SQL limerick!
This week started out with me posting about International Women’s Day, and has me personally attending Confoo (Montreal) which is an excellent conference I hope to return to next year. I learned a lot from confoo, especially the blending nosql and sql session I attended.
This week was also the Hotsos Symposium. Doug’s Oracle Blog has a series of posts about Hotsos. If all this talk about conferences has gotten you excited, Joshua Drake notes that 14 days and the hotel is almost full for postgresql conference east which is March 25th-28th in Philadelphia. And the Oracle database insider notes that the Oracle OpenWorld call for papers is now open.
According to Susan Visser this week (ending tomorrow) is also read an e-book week. So if you have not already done so, read an e-book! She links a coupon for an e-book in the post.
Craig Mullins notes that the mainframe is a good career choice in Mainframes: The Safe IT Career Choice. He notes that the mainframe is still not dead:
People having been predicting the death of the mainframe since the advent of client/server in the late 1980s. That is more than 20 years! Think of all the things that have died in that timespan while the mainframe keeps on chugging away: IBM’s PC business, Circuit City, Koogle peanut butter, public pay phones, Johnny Cash… the list is endless.
In other career-related news, Antonio Cangiano is looking for [2] top-notch student hackers for a 16-month internship at IBM in Toronto starting in May. All the details, including how to apply, are in Cangiano’s blog post.
Willie Favero wants to know how you “solve the batch dilemma” for issues like “shrinking your batch window, designing your batch to play nicely with … OLTP” in how’s your batch workload doing? Perhaps Favero should read the updated batch best practices posted by Anthony Shorten.
Bryan Smith surveys a more personal question by asking if you go both ways and “manage both DB2 for Linux, UNIX, and Windows and DB2 for z/OS” in don’t ask, don’t tell, bi-platform DBAs. This week’s Log Buffer editor admits to being a tri-platform DBA — she has tried many platforms, and in fact, many databases (MySQL, Oracle, DB2, SQL Server, Sybase, Postgres and Ingres)!
Hari Prasanna Srinivasan promotes a patching survey in Oracle really wants to hear from you! Patching Survey.
Henrik Loeser explains what a deadlock and a hot spot are by using a real life analogy taken from a police report in deadlock and hot spot in real life.
Jamie Thomson asks why do you abbreviate schema names?. Shlomi Noach tries to solve the issue that “there is no consistent convention as for how to write [about table aliases in] an SQL query” in proper sql table alias use conventions. Noach also gives us a tip: faster than truncate.
Leons Petrazickis reminds us that “rulesets are chains” and it is important to have your rulesets in the proper order in iptables firewall pitfall.
Anyone interested in the history of MySQL AB will be informed after reading Dries Buytaert’s article.
Gavin Towey shares his software that helps centrally manage 120 MySQL servers in qsh.pl: distributed query tool For those who want to learn more about column-oriented databases, particularly in MySQL, Robin Schumacher of the InfiniDB blog announces that there is a MySQL University session recording on MySQL column databases now available. MySQL join-fu expert Jay Pipes has moved his blog to www.joinfu.com and starts with An SQL Puzzle and of course a follow up on the sql puzzle.
Ivan Zoratti is happy that finally, slides posted for the MySQL DW breakfast. Venu Anuganti gives you tips on one of the most common MySQL frustrations: optimizing subqueries in how to improve subqueries derived tables performance. Justin Swanhart posts the way in which he Gets Linux performance information from your MySQL database without shell access and emulates a ‘top’ CPU summary using /proc/stat and MySQL using the same method.
The Oracle Apps blog has an introduction to Oracle user productivity kit (UPK). Even though in this editor’s opinion the article is very sales-pitchy, it has valuable information, and does indeed live up to its promise:
UPK is a software tool that can capture all the steps in a system process. It records every keystroke, every click of the mouse, each menu option chosen and each button pressed. All this is done in the UPK Recorder by going through the transaction and pressing “printscreen” after every user action. From this, without any further effort from the developer, UPK builds a number of valuable outputs.
Allen White gives a great tip on how to optimize queries in keep your data clean.
Mike Dietrich reminds you to remove “old” parameters and events from your init.ora when upgrading, “as keeping them will definitely slow down the database performance in the new release.” He shows evidence of slowness when this is not done. Dietrich also shows how you can be gathering workload statistics “to give the optimizer some good knowledge about how powerful your IO-system might be”, especially “a few days after upgrading to the new release…while a real workload is running.”
Brian Aker shows the exciting features coming soon in Drizzle in Drizzle, Cherry, Roadmap for our Next Release.
Maybe you are thinking of migrating, not upgrading…..The O’Reilly Radar shows how to asses an Oracle to MySQL migration in MySQL migration and risk management. Actually, that article interviews Ronald Bradford on the subject — Bradford has been prolific lately, updating free my.cnf advice series and “Don’t Assume”: MySQL for the Oracle DBA series. Nick Quarmby also talks about migrating Oracle, but not to a new database, just to a new platform, in his primer on migrating Oracle Applications to new platforms. And the big news comes from Carlos of dataprix that Twitter will migrate from MySQL to Cassandra DB.
Paul S. Randal explains his way of benchmarking: 1 Tb table population on SQL Server.
Pete Finnigan shares his slides from a webinar on how to secure oracle, and Denis Pilipchuk shares his approaches for discovering security vulnerabilities in software applications.
Jeff Davis shares his thoughts about scalability and the relational model. Robert Treat responds actually, the relational model doesn’t scale and Baron Schwartz counters with NoSQL doesn’t mean non-relational.
Buck Woody explains “whenever you want to know something about SQL Server’s configuration, whether that’s the Instance itself or a database, you have a few options” — and of course what those options are — in system variables, stored procedures or functions for meta data.
This week’s T-SQL Tuesday topic was I/O. There are many links to great blog posts in the comments; three random posts I chose to highlight: Michael Zilberstein talks about IO capacity planning, while Kalen Delaney talks about using STATISTICS IO in I/O, you know, and Merrill Aldrich chimes in with information on real world SSD’s. Aldrich also begs folks not to waste resources and make more work for developers and DBAs in dear ISV, you’re keeping me awake nights with your VARCHAR() dates.
And we end with a bit of fin: Paul Nielsen wants us all to have a bit of fun; he has posted an SQL limerick and asks readers to create there own in there once was in Dublin a query.
Persistence Smoothie: Blending NoSQL and SQL – see user feedback and comments at http://joind.in/talk/view/1332.
Michael Bleigh from Intridea, high-end Ruby and Ruby on Rails consultants, build apps from start to finish, making it scalable. He’s written a lot of stuff, available at http://github.com/intridea. @mbleigh on twitter
NoSQL is a new way to think about persistence. Most NoSQL systems are not ACID compliant (Atomicity, Consistency, Isolation, Durability).
Generally, most NoSQL systems have:
- Denormalization
- Eventual Consistency
- Schema-Free
- Horizontal Scale
NoSQL tries to scale (more) simply, it is starting to go mainstream – NY Times, BBC, SourceForge, Digg, Sony, ShopWiki, Meebo, and more. But it’s not *entirely* mainstream, it’s still hard to sell due to compliance and other reasons.
NoSQL has gotten very popular, lots of blog posts about them, but they reach this hype peak and obviously it can’t do everything.
“NoSQL is a (growing) collection of tools, not a new way of life.”
What is NoSQL? Can be several things:
- Key-Value Stores
- Document Databases
- Column-oriented data stores
- Graph Databases
Key-Value Stores
memcached is a “big hash in the sky” – it is a key value store. Similarly, NoSQL key-value stores “add to that big hash in the sky” and store to disk.
Speaker’s favorite is Redis because it’s similar to memcached.
- key-value store + datatypes (list, sets, scored sets, soon hashes will be there)
- cache-like functions (like expiration)
- (Mostly) in-memory
Another interesting key-value store is Riak
- Combination of key-value store and document database
- heavy into HTTP REST
- You can create links between documents, and do “link walking” that you don’t normally get out of a key-value store
- built-in Map Reduce
Map Reduce:
- Massively parallel way to process large datasets
- First you scour data and “map” a new set of dataM
- Then you “reduce” the data down to a salient result — for example, map reduce function to make a tag cloud: map function makes an array with a tag name and a count of 1 for each instance of that tag, and the reduce tag goes through that array and counts them…
- http://en.wikipedia.org/wiki/MapReduce
Other key-value stores:
Document Databases
Some say that it’s the “closest” thing to real SQL.
- MongoDB – Document store that speaks BSON (Binary JSON, which is compact). This is the speaker’s favorite because it has a rich query syntax that makes it close to SQL. Can’t do joins, but can embed objects in other objects, so it’s a tradeoff
- Also has GridFS that can store large files efficiently, can scale to petabytes of data
- does have MapReduce but it’s deliberate and you run it every so often.
- CouchDB
- Pure JSON Document Store – can query directly with nearly pure javascript (there are auth issues) but it’s an interesting paradigm to be able to run your app almost entirely through javascript.
- HTTP REST interface
- MapReduce only to see items in CouchDB. Incremental MapReduce, every time you add or modify a document, it dynamically changes the functions you’ve written. You can do really powerful queries as easy as you can do simple queries. However, some things are really complex, ie, pagination is almost impossible to do.
- Intelligent Replication – CouchDB is designed to work with offline integration. Could be used instead of SQLite as the HTML5 data store, but you need CouchDB running locally to be doing offline stuff w/CouchDB
Column-oriented store
Columns are stored together (ie, names) instead of rows. Lets you be schema-less because you don’t care about a row’s consistency, you can just add a column to a table very easily.
Graph Databases
speaker’s opinion – there aren’t enough of these.
Neo4J – can handle modeling complex relationships – “friends of friends of cousins” but it requires a license.
When should I use this stuff?
| If you have: | Use |
|---|
| Complex, slow joins for an “activity stream” | Denormalize, use a key-value store. |
| Variable schema, vertical interaction | Document database or column store |
| Modeling multi-step relationships (linkedin, friends of friends, etc) | Graph |
Don’t look for a single tool that does every job. Use more than one if it’s appropriate, weigh the tradeoffs (ie, don’t have 7 different data stores either!)
NoSQL solves real scalability and data design issues. But financial transactions HAVE to be atomic, so don’t use NoSQL for those.
A good presentation is http://www.slideshare.net/bscofield/the-state-of-nosql.
Using SQL and NoSQL together
Why? Well, your data is already in an SQL database (most likely).
You can blend by hand, but the easy way is DataMapper:
Generic, relational ORM (adapters for many SQL dbs and many NoSQL stores)
Implements Identity Map
Module-based inclusion (instead of extending from a class, you just include into a class).
You can set up multiple data targets (default is MySQL, example sets up MongoDB too).
DataMapper is:
- Ultimate Polyglot ORM
- simple r’ships btween persistence engines are easy
- jack of all, master none
- Sometimes perpetuates false assumptions –
- If you’re in Ruby, your legacy stuff is in ActiveRecord, so you’re going to have to rewrite your code anyway.
Speaker’s idea to be less generic and better use of features of each data store – Gloo – “Gloo glues together different ORMs by providing relationship proxies.” this software is ALPHA ALPHA ALPHA.
The goal is to be able to define relationships on the terms of any ORM from any class, ORM or not
Right now – partially working activeRecord relationships
Is he doing it wrong? Is it a crazy/stupid idea? Maybe.
Example:
| Need | Use |
| Assume you already have an auth system | it’s already in SQL, so leave it there. |
| Need users to be able to purchase items from the storefront – Can’t lose transactions, need full ACID compliance | use MySQL. |
| Social Graph – want to have activity streams and 1-way and 2-way relationships. Need speed, but not consistency | use Redis |
| Product Listings — selling moves and books, both have different properties, products are pretty much non-relational | use MongoDB |
He wrote the example in about 3 hours, so integration of multiple data stores can be done quickly and work.
Persistence Smoothie: Blending NoSQL and SQL – see user feedback and comments at http://joind.in/talk/view/1332.
Michael Bleigh from Intridea, high-end Ruby and Ruby on Rails consultants, build apps from start to finish, making it scalable. He’s written a lot of stuff, available at http://github.com/intridea. @mbleigh on twitter
NoSQL is a new way to think about persistence. Most NoSQL systems are not ACID compliant (Atomicity, Consistency, Isolation, Durability).
Generally, most NoSQL systems have:
- Denormalization
- Eventual Consistency
- Schema-Free
- Horizontal Scale
NoSQL tries to scale (more) simply, it is starting to go mainstream – NY Times, BBC, SourceForge, Digg, Sony, ShopWiki, Meebo, and more. But it’s not *entirely* mainstream, it’s still hard to sell due to compliance and other reasons.
NoSQL has gotten very popular, lots of blog posts about them, but they reach this hype peak and obviously it can’t do everything.
“NoSQL is a (growing) collection of tools, not a new way of life.”
What is NoSQL? Can be several things:
- Key-Value Stores
- Document Databases
- Column-oriented data stores
- Graph Databases
Key-Value Stores
memcached is a “big hash in the sky” – it is a key value store. Similarly, NoSQL key-value stores “add to that big hash in the sky” and store to disk.
Speaker’s favorite is Redis because it’s similar to memcached.
- key-value store + datatypes (list, sets, scored sets, soon hashes will be there)
- cache-like functions (like expiration)
- (Mostly) in-memory
Another interesting key-value store is Riak
- Combination of key-value store and document database
- heavy into HTTP REST
- You can create links between documents, and do “link walking” that you don’t normally get out of a key-value store
- built-in Map Reduce
Map Reduce:
- Massively parallel way to process large datasets
- First you scour data and “map” a new set of dataM
- Then you “reduce” the data down to a salient result — for example, map reduce function to make a tag cloud: map function makes an array with a tag name and a count of 1 for each instance of that tag, and the reduce tag goes through that array and counts them…
- http://en.wikipedia.org/wiki/MapReduce
Other key-value stores:
Document Databases
Some say that it’s the “closest” thing to real SQL.
- MongoDB – Document store that speaks BSON (Binary JSON, which is compact). This is the speaker’s favorite because it has a rich query syntax that makes it close to SQL. Can’t do joins, but can embed objects in other objects, so it’s a tradeoff
- Also has GridFS that can store large files efficiently, can scale to petabytes of data
- does have MapReduce but it’s deliberate and you run it every so often.
- CouchDB
- Pure JSON Document Store – can query directly with nearly pure javascript (there are auth issues) but it’s an interesting paradigm to be able to run your app almost entirely through javascript.
- HTTP REST interface
- MapReduce only to see items in CouchDB. Incremental MapReduce, every time you add or modify a document, it dynamically changes the functions you’ve written. You can do really powerful queries as easy as you can do simple queries. However, some things are really complex, ie, pagination is almost impossible to do.
- Intelligent Replication – CouchDB is designed to work with offline integration. Could be used instead of SQLite as the HTML5 data store, but you need CouchDB running locally to be doing offline stuff w/CouchDB
Column-oriented store
Columns are stored together (ie, names) instead of rows. Lets you be schema-less because you don’t care about a row’s consistency, you can just add a column to a table very easily.
Graph Databases
speaker’s opinion – there aren’t enough of these.
Neo4J – can handle modeling complex relationships – “friends of friends of cousins” but it requires a license.
When should I use this stuff?
| If you have: | Use |
|---|
| Complex, slow joins for an “activity stream” | Denormalize, use a key-value store. |
| Variable schema, vertical interaction | Document database or column store |
| Modeling multi-step relationships (linkedin, friends of friends, etc) | Graph |
Don’t look for a single tool that does every job. Use more than one if it’s appropriate, weigh the tradeoffs (ie, don’t have 7 different data stores either!)
NoSQL solves real scalability and data design issues. But financial transactions HAVE to be atomic, so don’t use NoSQL for those.
A good presentation is http://www.slideshare.net/bscofield/the-state-of-nosql.
Using SQL and NoSQL together
Why? Well, your data is already in an SQL database (most likely).
You can blend by hand, but the easy way is DataMapper:
Generic, relational ORM (adapters for many SQL dbs and many NoSQL stores)
Implements Identity Map
Module-based inclusion (instead of extending from a class, you just include into a class).
You can set up multiple data targets (default is MySQL, example sets up MongoDB too).
DataMapper is:
- Ultimate Polyglot ORM
- simple r’ships btween persistence engines are easy
- jack of all, master none
- Sometimes perpetuates false assumptions –
- If you’re in Ruby, your legacy stuff is in ActiveRecord, so you’re going to have to rewrite your code anyway.
Speaker’s idea to be less generic and better use of features of each data store – Gloo – “Gloo glues together different ORMs by providing relationship proxies.” this software is ALPHA ALPHA ALPHA.
The goal is to be able to define relationships on the terms of any ORM from any class, ORM or not
Right now – partially working activeRecord relationships
Is he doing it wrong? Is it a crazy/stupid idea? Maybe.
Example:
| Need | Use |
| Assume you already have an auth system | it’s already in SQL, so leave it there. |
| Need users to be able to purchase items from the storefront – Can’t lose transactions, need full ACID compliance | use MySQL. |
| Social Graph – want to have activity streams and 1-way and 2-way relationships. Need speed, but not consistency | use Redis |
| Product Listings — selling moves and books, both have different properties, products are pretty much non-relational | use MongoDB |
He wrote the example in about 3 hours, so integration of multiple data stores can be done quickly and work.
Most of this stuff is not PHP specific, and Python or Ruby or Java or .NET developers can use the tools in this talk.
The session on joind.in, with user comments/feedback, is at http://joind.in/talk/view/1320.
Slides are at http://talks.php.net/show/confoo10
“My name is Rasmus, I’ve been around for a long time. I’ve been doing this web stuff since 1992/1993.”
“Generally performance is not a PHP problem.” Webservers not config’d, no expire headers on images, no favicon.
Tools: Firefox/Firebug extension called YSlow (developed by yahoo) gives you a grade on your site.
Google has developed the Firefox/Firebug pagespeed tool.
Today Rasmus will pick on wordpress. He checks out the code, then uses Siege to do a baseline benchmark — see the slide for the results.
Before you do anything else install an opcode cache like APC. Wordpress really likes this type of caching, see this slide for the results. Set the timezone, to make sure conversions aren’t being done all the time.
Make sure you are cpu-bound, NOT I/O bound. Otherwise, speed up the I/O.
Then strace your webserver processs. There are common config issues that you can spot in your strace code. grep for ENOENT which shows you “No such file or directory” errors.
AllowOverride None to turn off .htaccess for every directory, just read settings once from your config file….(unless you’re an ISP).
Make sure DirectoryIndex is set appropriately, watch your include_path. All this low-hanging fruit has examples on the common config issues slide.
Install pecl/inclued and generate a graph – here is the graph image (I have linked it because you really want to zoom in to the graph…)
In strace output check the open() calls. Conditional includes, function calls that include files, etc. need runtime context before knowing what to open. In the example, every request checks to see if we have the config file, once we have config’d we can get rid of that stuff. Get rid of all the conditionals and hard-code “include wp-config.php”. Examples are on the slide.
His tips to change:
Conditional config include in wp-load.php (as just mentioned)
Conditional did-header check in wp-blog-header.php
Don’t call require_wp_db() from wp-settings.php
Remove conditional require logic from wp_start_object_cache
Then check strace again, now all Rasmus sees is theming and translations, which he decided to keep, because that’s the good benefit of Wordpress – Performance is all about costs vs. flexibility. You don’t want to get rid of all of your flexibility, but you want to be fast.
Set error_reporting(-1) in wp-settings.php to catch all warnings — warnings slow you down, so get rid of all errors. PHP error handling is very slow, so getting rid of errors will make you faster.
The slide of warnings that wordpress throws.
Look at all C-level calls made, using callgrind, which sits under valgrind, a CPU emulator used for debugging. See the image of what callgrind shows.
Now dive into the PHP executor, by installing XDebug.
Check xhprof – Facebook open sourced this about a year ago, it’s a PECL extension. The output is pretty cool, try it on your own site, Rasmus does show you how to use it. It shows you functions sorted by the most expensive to the least expensive.
For example, use $_SERVER[REQUEST_TIME] instead of time(). Use pconnect() if MySQL can handle the amount of webserver connections that will be persistent, etc.
After you have changed a lot of the stuff above, benchmark again with siege to see how much faster you are. In this case there is not much gained so far.
So keep going….the blogroll is very slow — Rasmus gets rid of it by commenting out in the sidebar.php file. I’d like to see something to make it “semi-dynamic” — that is, make it a static file that can be re-generated, since you might want the blogroll but links are not changed every second…..
At this point we’re out of low-hanging fruit.
HipHop is a PHP to C++ converter & compiler, including a threaded, event-driven server that replaces apache. Rasmus’ slide says “Wordpress is well-suited for HipHop because it doesn’t have a lot of dynamic runtime code. This is using the standard Wordpress-svn checkout with a few tweaks.”
Then, of course, benchmark again.
The first time you compile Wordpress with HipHop, you give it a list of files to add to the binary, it will complain about php code that generate file names, so you do have to fix that kind of stuff. There’s a huge mess of errors the first time you run it (”pages and pages”), and Rasmus had to patch HipHop (and Wordpress) but the changes in HipHop have been put back into HipHop, so you should be good for the most part.
Check out the errors, lots of them show logical errors like $foo.”bar” instead of $foo.=”bar” and $foo=”bar” instead of $foo==”bar” in an if statement. Which of course is nice for your own code, to find those logical errors.
(Wordpress takes in a $user_ID argument and immediately initializes a global $user_ID variable, which overwrites the argument passed in, so you can change the name of the argument passed in….)
You can also get rid of some code, things that check for existence of the same thing more than once. So it will take a bit of tweaking, but it’s worth it.
There are limitations to HipHop, for example:
- It doesn’t support any of the new PHP 5.3 language features
- Private properties don’t really exist under HipHop. They are treated as if they are protected instead.
- You can’t unset variables. unset will clear the variable, but it will still be in the symbol table.
- eval and create_function are limited
- Variable variables $$var are not supported
- Dynamic defines won’t work: define($name,$value)
- get_loaded_extensions(), get_extension_funcs(), phpinfo(), debug_backtrace() don’t work
- Conditional and dynamically created include filenames don’t work as you might expect
- Default unix-domain socket filename isn’t set for MySQL so connecting to localhost doesn’t work
and HipHop does not support all extensions — see the list Rasmus has of extensions HipHop supports.
Then Rasmus showed an example using Twit (which he wrote) including the benchmarks. He shows that you can see what’s going on, like 5 MySQL calls on the home page and what happens when you don’t have a favicon.ico (in yellow).
In summary, “performance is all about architecture”, “know your costs”.
Be careful, because some tools (like valgrind and xdebug) you don’t want to put it on production systems, you could capture production traffic and replay it on a dev/testing box, but “you just have to minimize the differences and do your best”.
Most of this stuff is not PHP specific, and Python or Ruby or Java or .NET developers can use the tools in this talk.
The session on joind.in, with user comments/feedback, is at http://joind.in/talk/view/1320.
Slides are at http://talks.php.net/show/confoo10
“My name is Rasmus, I’ve been around for a long time. I’ve been doing this web stuff since 1992/1993.”
“Generally performance is not a PHP problem.” Webservers not config’d, no expire headers on images, no favicon.
Tools: Firefox/Firebug extension called YSlow (developed by yahoo) gives you a grade on your site.
Google has developed the Firefox/Firebug pagespeed tool.
Today Rasmus will pick on wordpress. He checks out the code, then uses Siege to do a baseline benchmark — see the slide for the results.
Before you do anything else install an opcode cache like APC. WordPress really likes this type of caching, see this slide for the results. Set the timezone, to make sure conversions aren’t being done all the time.
Make sure you are cpu-bound, NOT I/O bound. Otherwise, speed up the I/O.
Then strace your webserver processs. There are common config issues that you can spot in your strace code. grep for ENOENT which shows you “No such file or directory” errors.
AllowOverride None to turn off .htaccess for every directory, just read settings once from your config file….(unless you’re an ISP).
Make sure DirectoryIndex is set appropriately, watch your include_path. All this low-hanging fruit has examples on the common config issues slide.
Install pecl/inclued and generate a graph – here is the graph image (I have linked it because you really want to zoom in to the graph…)
In strace output check the open() calls. Conditional includes, function calls that include files, etc. need runtime context before knowing what to open. In the example, every request checks to see if we have the config file, once we have config’d we can get rid of that stuff. Get rid of all the conditionals and hard-code “include wp-config.php”. Examples are on the slide.
His tips to change:
Conditional config include in wp-load.php (as just mentioned)
Conditional did-header check in wp-blog-header.php
Don’t call require_wp_db() from wp-settings.php
Remove conditional require logic from wp_start_object_cache
Then check strace again, now all Rasmus sees is theming and translations, which he decided to keep, because that’s the good benefit of WordPress – Performance is all about costs vs. flexibility. You don’t want to get rid of all of your flexibility, but you want to be fast.
Set error_reporting(-1) in wp-settings.php to catch all warnings — warnings slow you down, so get rid of all errors. PHP error handling is very slow, so getting rid of errors will make you faster.
The slide of warnings that wordpress throws.
Look at all C-level calls made, using callgrind, which sits under valgrind, a CPU emulator used for debugging. See the image of what callgrind shows.
Now dive into the PHP executor, by installing XDebug.
Check xhprof – Facebook open sourced this about a year ago, it’s a PECL extension. The output is pretty cool, try it on your own site, Rasmus does show you how to use it. It shows you functions sorted by the most expensive to the least expensive.
For example, use $_SERVER[REQUEST_TIME] instead of time(). Use pconnect() if MySQL can handle the amount of webserver connections that will be persistent, etc.
After you have changed a lot of the stuff above, benchmark again with siege to see how much faster you are. In this case there is not much gained so far.
So keep going….the blogroll is very slow — Rasmus gets rid of it by commenting out in the sidebar.php file. I’d like to see something to make it “semi-dynamic” — that is, make it a static file that can be re-generated, since you might want the blogroll but links are not changed every second…..
At this point we’re out of low-hanging fruit.
HipHop is a PHP to C++ converter & compiler, including a threaded, event-driven server that replaces apache. Rasmus’ slide says “WordPress is well-suited for HipHop because it doesn’t have a lot of dynamic runtime code. This is using the standard WordPress-svn checkout with a few tweaks.”
Then, of course, benchmark again.
The first time you compile WordPress with HipHop, you give it a list of files to add to the binary, it will complain about php code that generate file names, so you do have to fix that kind of stuff. There’s a huge mess of errors the first time you run it (”pages and pages”), and Rasmus had to patch HipHop (and WordPress) but the changes in HipHop have been put back into HipHop, so you should be good for the most part.
Check out the errors, lots of them show logical errors like $foo.”bar” instead of $foo.=”bar” and $foo=”bar” instead of $foo==”bar” in an if statement. Which of course is nice for your own code, to find those logical errors.
(WordPress takes in a $user_ID argument and immediately initializes a global $user_ID variable, which overwrites the argument passed in, so you can change the name of the argument passed in….)
You can also get rid of some code, things that check for existence of the same thing more than once. So it will take a bit of tweaking, but it’s worth it.
There are limitations to HipHop, for example:
- It doesn’t support any of the new PHP 5.3 language features
- Private properties don’t really exist under HipHop. They are treated as if they are protected instead.
- You can’t unset variables. unset will clear the variable, but it will still be in the symbol table.
- eval and create_function are limited
- Variable variables $$var are not supported
- Dynamic defines won’t work: define($name,$value)
- get_loaded_extensions(), get_extension_funcs(), phpinfo(), debug_backtrace() don’t work
- Conditional and dynamically created include filenames don’t work as you might expect
- Default unix-domain socket filename isn’t set for MySQL so connecting to localhost doesn’t work
and HipHop does not support all extensions — see the list Rasmus has of extensions HipHop supports.
Then Rasmus showed an example using Twit (which he wrote) including the benchmarks. He shows that you can see what’s going on, like 5 MySQL calls on the home page and what happens when you don’t have a favicon.ico (in yellow).
In summary, “performance is all about architecture”, “know your costs”.
Be careful, because some tools (like valgrind and xdebug) you don’t want to put it on production systems, you could capture production traffic and replay it on a dev/testing box, but “you just have to minimize the differences and do your best”.
subtitle: Monetizing Social Media
Why is social media and social networking essential to you and your business? (because it will drive sales, but there’s very few analytics for ROI on social networking and social media)
Relying on advertising is no longer working for print newspapers and television. So why do we think it will work on internet media?
Blogging — you must post 2-4 quality blog posts every week to maintain readership. This takes a lot of work! Content is king.
No matter how cool the technology/product/service is, people still buy more often and more easily from people they know and trust.
Social media is a way to show people that you are an industry expert, and that is how you should use them (not to spam and only say “buy my product”).
If you do not love your job and try to sell it (say, on social networking), you are going to fail, because you are not passionate about it.
Start small, do not promise a lot, it is better to have more to say than to have dead air time (radio analogy).
Social media is all about building good relationships by having good content that people trust.
Lots of people spend a lot of money on their website, but the website is just a vector to show people your content, and the content is the most important thing.
Cross-pollination – I think he means forward on information you learn (like, say, liveblogging!)
Get expert guest bloggers — he did not explain that you can leverage the relationships you form by asking them to blog. We do this with the Log Buffers….
How to make money:
sponsorships
white paper composition
paid articles
consulting
adjunct tie-ins to other related venues
branded blogs
I am personally disappointed because I wanted to learn more, and I feel as though Pythian already uses the knowledge presented — we have great exposure through our blog, and have started really using Twitter, Facebook and other social media sites, etc.
Hansen’s information was good, and absolutely 100% correct, but I felt that for me it was very basic. I would like to know some more advanced topics, like:
– How do you know when you have reached the tipping point?
– How do you convert anonymous readers/followers to people you know, without turning them away because they feel they’re being watched, spammed or don’t want to give out their info to you?
– When does copy/paste to send out your information start to bother people, how do you know how not to do too much?
– How do you convert readers/followers (anon or not) to paid customers without making them feel like you’re all about $$, what about if you have some free content and some paid content, how do you know how much to have?
subtitle: Monetizing Social Media
Why is social media and social networking essential to you and your business? (because it will drive sales, but there’s very few analytics for ROI on social networking and social media)
Relying on advertising is no longer working for print newspapers and television. So why do we think it will work on internet media?
Blogging — you must post 2-4 quality blog posts every week to maintain readership. This takes a lot of work! Content is king.
No matter how cool the technology/product/service is, people still buy more often and more easily from people they know and trust.
Social media is a way to show people that you are an industry expert, and that is how you should use them (not to spam and only say “buy my product”).
If you do not love your job and try to sell it (say, on social networking), you are going to fail, because you are not passionate about it.
Start small, do not promise a lot, it is better to have more to say than to have dead air time (radio analogy).
Social media is all about building good relationships by having good content that people trust.
Lots of people spend a lot of money on their website, but the website is just a vector to show people your content, and the content is the most important thing.
Cross-pollination – I think he means forward on information you learn (like, say, liveblogging!)
Get expert guest bloggers — he did not explain that you can leverage the relationships you form by asking them to blog. We do this with the Log Buffers….
How to make money:
sponsorships
white paper composition
paid articles
consulting
adjunct tie-ins to other related venues
branded blogs
I am personally disappointed because I wanted to learn more, and I feel as though Pythian already uses the knowledge presented — we have great exposure through our blog, and have started really using Twitter, Facebook and other social media sites, etc.
Hansen’s information was good, and absolutely 100% correct, but I felt that for me it was very basic. I would like to know some more advanced topics, like:
– How do you know when you have reached the tipping point?
– How do you convert anonymous readers/followers to people you know, without turning them away because they feel they’re being watched, spammed or don’t want to give out their info to you?
– When does copy/paste to send out your information start to bother people, how do you know how not to do too much?
– How do you convert readers/followers (anon or not) to paid customers without making them feel like you’re all about $$, what about if you have some free content and some paid content, how do you know how much to have?
What is confoo? It is the sequel to the PHP Quebéc Conference (2003 – 2009). This year PHP Quebec decided to team up with Montreal-Python, W3Quebéc and OWASP Montréal to produce confoo.
And now, on to Mark Pilgrim of Google speaking on HTML5.
Timeline
1991 – HTML 1
1994 – HTML 2
1995 – Netscape discovers web, ruins it
1996 – CSS1 + JavaScript
1996 – Microsoft discovers web, ruins it
1997 – HTML4 + EMCAScript1
1998 – CSS2 + EMCAScript2 + DOM1
2000 – XHTML1 + EMCAScript3 + DOM2
2001 – XHTML 1.1
[long break!]
2009 – HTML 5 + ECMA5 + CSS 2.1
HTML5 is not a spec, it’s a marketing term. It’s really HTML5 + CSS3 + JavaScript.
IsHTML5ReadyYet.com and IsHTML5Ready.com are both real websites that give different answers to the question “is HTML 5 ready?”
Semantics
HTML started as a semantic language (until Netscape came along).
New elements (html tags) that do not do anything – they are for semantic use only:
<header> <footer>
<section>
<article>
<nav>
<aside> (pull quotes and such)
<time> (datetime markup)
<mark> (marking up runs of text)
<figure> <figcaption>
Instead of “div class=_____” use these tags….for example:
<body>
<header>
<hgroup>
<h2>page title</h2>
<h3>page subtitle</h3>
</hgroup>
</header>
<nav>
<ul> Navigation......
.....
</ul>
</nav>
<section>
<article>
<header>
<h2>Title</h2>
</header>
</section>
Caveat: This doesn’t work in IE but there is a workaround…..
This can help blind people navigate better….and bots too!
“Google is just another blind web user with 7 million friends”
Forms
Web forms 2.0
To make a slider from 0-50:
<input type='range' mix='0' max='50' value='0'></input>
To use autofocus:
<input autofocus>
(works in 3 browsers)
Talking about blind users again: “Focus tracking is VERY important if you can’t see. You really need to know where on the page you are, if you start typing what will happen.”
Placeholder text — in a text box, that light text that goes away when you click:
<input type='text' placeholder='click here and this will disappear'>
(works in 2 browsers)
New input types
These are semantic types, do different things in different browsers
<input type='email'> (on the iphone you get a different keyboard, by default you just get a textfield, so these things degrade gracefully if the browser does not support the feature)
<input type='url'> (a browser like <A HREF="http://www.opera.com">Opera</A> can validate a URL for you instead of you doing it yourself!)
<input type='datetime'> (and more...date pickers are tedious)
<input type='file' multiple> (multiple files without using flash!)
For all the inputs HTML5 supports and which browsers support them (Opera is leading the way) search for “HTML5 input support”
Accessibility
ARIA = “accessible rich internet applications”. Alt-text is technology that’s long behind. ARIA does stuff like making tree views accessible. For example, right now with a tree view you have to tab through each item, which is a pain. With code like this:
<ul id='tree1' role='tree' tabindex='0' aria-labelledby='label_1'>
<li role='treeitem' tabindex='-1' aria-expanded='true'>Fruits </li>
<li role='group'>
<ul>
<li role='treeitem' tabindex='-1'>Oranges</li>
<li role='treeitem' tabindex='-1'>Pineapples</li>
</ul>
</li>
</ul>
….keyboard users can tab to the treeview itself, then use arrow keys to navigate and spacebar to select. This makes selecting an item at the end of a tree view much easier, and also makes it easy to move beyond the tree view without having to press Tab a million times.
Use your favorite search engine for “ARIA accessibility” to learn more.
CSS
Mark threw this image up on the screen:

(image from http://www.zazzle.com/stevenfrank – on that site you can buy this coffee mug or a T-shirt with the design)
Web fonts finally work in CSS3 – you can use more than Times, Courier, Arial, and occasionally Helvetica. This works EVERYWHERE – Chrome, IE, Firefox, Opera, Safari, etc. Well, it’s true that they all use it, but they all have different fonts they support. Read Bulletproof font face for tips on how to get the font you want no matter what browser is used (yes, even IE).
Opacity is easy [author’s note – it’s just the “opacity” element, see examples at http://www.css3.info/preview/opacity/].
Rounded corners are EASY – Mark’s slide passed too fast for me, so I grabbed an example from http://24ways.org/2006/rounded-corner-boxes-the-css3-way:
.box {
border-radius: 1.6em;
}
Gradients are easy [author’s note — looks like you need webkit, there’s examples at http://gradients.glrzad.com/]
To test CSS3 stuff, use www.css3please.com – “This element will receive inline changes as you edit the CSS rules on the left.”
[Author’s note — while searching I found http://www.webappers.com/2009/08/10/70-must-have-css3-and-html5-tutorials-and-resources/ which is definitely a “must have”.]
Canvas
A canvas is a blank slate where you can draw whatever you want, use the canvas tag and id, width and height attributes, everything else is javascript. Pretty awesome. [Author’s note — Mark had examples but I did not have time to capture them. I did find a nice tutorial at https://developer.mozilla.org/en/Canvas_tutorial.]
Multimedia
Video with no flash! YouTube has HTML5 integration. Here’s sample code of how to do movies in HTML5:
<video src='movie.ogv' controls></video>
<video src='movie.ogv' loop></video>
<video src='movie.ogv' preload='none'></video> -- don't preload the movie
<video src='movie.ogv' preload='auto'></video>
<video src='movie.ogv' autoplay></video> -- if you don't have this you don't do evil autoplay....
Multimedia is in the DOM and responds to CSS effects, such as reflection:
<video src='movie.ogv' loop style='webkit-box-reflect: below 1px;'></video>
(this code might be wrong, the slide flipped fast)
Of course the problem — codecs. Right now, .ogv and .mp4 (h264).
Audio inline too, same problem — only .oga and .mp3:
<audio src ='podcast.oga' controls></audio>
Geolocation
IsGeolocationPartofHTML5.com is a real site, go to it to get the answer.
Geolocation demos — very much the same, find your location and display it. Simple but cool.
Cache manifest
Get everything you need for offline usage…
<html manifest='another-sky.manifest'>
CACHE MANIFEST
/avatars/zoe.png
/avatars/tamara.png
/scripts/holoband.jpg
search for “google for mobile HTML5 series” – good series of articles on using this stuff.
HTML 5 has much more
Local storage
Web workers
Web sockets (2way connections, like raw tcp/ip cxns over the web)
3D canvas (webgl)
Microdata (enhanced semantics)
Desktop notifications
Drag and Drop
Learn more:
whatwg.org/html5
diveintohtml5.org
What is confoo? It is the sequel to the PHP Quebéc Conference (2003 – 2009). This year PHP Quebec decided to team up with Montreal-Python, W3Quebéc and OWASP Montréal to produce confoo.
And now, on to Mark Pilgrim of Google speaking on HTML5.
Timeline
1991 – HTML 1
1994 – HTML 2
1995 – Netscape discovers web, ruins it
1996 – CSS1 + JavaScript
1996 – Microsoft discovers web, ruins it
1997 – HTML4 + EMCAScript1
1998 – CSS2 + EMCAScript2 + DOM1
2000 – XHTML1 + EMCAScript3 + DOM2
2001 – XHTML 1.1
[long break!]
2009 – HTML 5 + ECMA5 + CSS 2.1
HTML5 is not a spec, it’s a marketing term. It’s really HTML5 + CSS3 + JavaScript.
IsHTML5ReadyYet.com and IsHTML5Ready.com are both real websites that give different answers to the question “is HTML 5 ready?”
Semantics
HTML started as a semantic language (until Netscape came along).
New elements (html tags) that do not do anything – they are for semantic use only:
<header> <footer>
<section>
<article>
<nav>
<aside> (pull quotes and such)
<time> (datetime markup)
<mark> (marking up runs of text)
<figure> <figcaption>
Instead of “div class=_____” use these tags….for example:
<body>
<header>
<hgroup>
<h2>page title</h2>
<h3>page subtitle</h3>
</hgroup>
</header>
<nav>
<ul> Navigation......
.....
</ul>
</nav>
<section>
<article>
<header>
<h2>Title</h2>
</header>
</section>
Caveat: This doesn’t work in IE but there is a workaround…..
This can help blind people navigate better….and bots too!
“Google is just another blind web user with 7 million friends”
Forms
Web forms 2.0
To make a slider from 0-50:
<input type='range' mix='0' max='50' value='0'></input>
To use autofocus:
<input autofocus>
(works in 3 browsers)
Talking about blind users again: “Focus tracking is VERY important if you can’t see. You really need to know where on the page you are, if you start typing what will happen.”
Placeholder text — in a text box, that light text that goes away when you click:
<input type='text' placeholder='click here and this will disappear'>
(works in 2 browsers)
New input types
These are semantic types, do different things in different browsers
<input type='email'> (on the iphone you get a different keyboard, by default you just get a textfield, so these things degrade gracefully if the browser does not support the feature)
<input type='url'> (a browser like <A HREF="http://www.opera.com">Opera</A> can validate a URL for you instead of you doing it yourself!)
<input type='datetime'> (and more...date pickers are tedious)
<input type='file' multiple> (multiple files without using flash!)
For all the inputs HTML5 supports and which browsers support them (Opera is leading the way) search for “HTML5 input support”
Accessibility
ARIA = “accessible rich internet applications”. Alt-text is technology that’s long behind. ARIA does stuff like making tree views accessible. For example, right now with a tree view you have to tab through each item, which is a pain. With code like this:
<ul id='tree1' role='tree' tabindex='0' aria-labelledby='label_1'>
<li role='treeitem' tabindex='-1' aria-expanded='true'>Fruits </li>
<li role='group'>
<ul>
<li role='treeitem' tabindex='-1'>Oranges</li>
<li role='treeitem' tabindex='-1'>Pineapples</li>
</ul>
</li>
</ul>
….keyboard users can tab to the treeview itself, then use arrow keys to navigate and spacebar to select. This makes selecting an item at the end of a tree view much easier, and also makes it easy to move beyond the tree view without having to press Tab a million times.
Use your favorite search engine for “ARIA accessibility” to learn more.
CSS
Mark threw this image up on the screen:
(image from http://www.zazzle.com/stevenfrank – on that site you can buy this coffee mug or a T-shirt with the design)
Web fonts finally work in CSS3 – you can use more than Times, Courier, Arial, and occasionally Helvetica. This works EVERYWHERE – Chrome, IE, Firefox, Opera, Safari, etc. Well, it’s true that they all use it, but they all have different fonts they support. Read Bulletproof font face for tips on how to get the font you want no matter what browser is used (yes, even IE).
Opacity is easy [author’s note – it’s just the “opacity” element, see examples at http://www.css3.info/preview/opacity/].
Rounded corners are EASY – Mark’s slide passed too fast for me, so I grabbed an example from http://24ways.org/2006/rounded-corner-boxes-the-css3-way:
.box {
border-radius: 1.6em;
}
Gradients are easy [author’s note — looks like you need webkit, there’s examples at http://gradients.glrzad.com/]
To test CSS3 stuff, use www.css3please.com – “This element will receive inline changes as you edit the CSS rules on the left.”
[Author’s note — while searching I found http://www.webappers.com/2009/08/10/70-must-have-css3-and-html5-tutorials-and-resources/ which is definitely a “must have”.]
Canvas
A canvas is a blank slate where you can draw whatever you want, use the canvas tag and id, width and height attributes, everything else is javascript. Pretty awesome. [Author’s note — Mark had examples but I did not have time to capture them. I did find a nice tutorial at https://developer.mozilla.org/en/Canvas_tutorial.]
Multimedia
Video with no flash! YouTube has HTML5 integration. Here’s sample code of how to do movies in HTML5:
<video src='movie.ogv' controls></video>
<video src='movie.ogv' loop></video>
<video src='movie.ogv' preload='none'></video> -- don't preload the movie
<video src='movie.ogv' preload='auto'></video>
<video src='movie.ogv' autoplay></video> -- if you don't have this you don't do evil autoplay....
Multimedia is in the DOM and responds to CSS effects, such as reflection:
<video src='movie.ogv' loop style='webkit-box-reflect: below 1px;'></video>
(this code might be wrong, the slide flipped fast)
Of course the problem — codecs. Right now, .ogv and .mp4 (h264).
Audio inline too, same problem — only .oga and .mp3:
<audio src ='podcast.oga' controls></audio>
Geolocation
IsGeolocationPartofHTML5.com is a real site, go to it to get the answer.
Geolocation demos — very much the same, find your location and display it. Simple but cool.
Cache manifest
Get everything you need for offline usage…
<html manifest='another-sky.manifest'>
CACHE MANIFEST
/avatars/zoe.png
/avatars/tamara.png
/scripts/holoband.jpg
search for “google for mobile HTML5 series” – good series of articles on using this stuff.
HTML 5 has much more
Local storage
Web workers
Web sockets (2way connections, like raw tcp/ip cxns over the web)
3D canvas (webgl)
Microdata (enhanced semantics)
Desktop notifications
Drag and Drop
Learn more:
whatwg.org/html5
diveintohtml5.org
If you do not know what International Women’s Day is: http://www.internationalwomensday.com/
Start planning your blog posts for Ada Lovelace day now (March 24th, http://findingada.com/ Ada Lovelace Day is an international day of blogging (videologging, podcasting, comic drawing etc.!) to draw attention to the achievements of women in technology and science.)
To that end, I would like to point out all the women currently in science and tech fields that I admire and think are doing great things. I think it would be great if everyone, male or female, made a list like this:
The women that have taught me science/tech along the way:
High School:
Mary Lou Ciavarra (Physics)
Maria Petretti (Pre-Algebra, and Academic Decathlon)
Reneé Fishman (Biology)
Lisa Acquaire (Economics during Academic Decathlon)
College:
Professor Kalpana White (Biology), and in whose fruit fly lab I worked for 2 semesters.
Professor Eve Marder (Introductory Neuroscience)
Though Brandeis does have female faculty in the Computer Science department, I did not manage to have any classes with female Computer Science faculty members.
My current female DBA co-workers at Pythian: Isabel Pinarci (Oracle), Michelle Gutzait (SQL Server), Catherine Chow (Oracle) and Jasmine Wen (Oracle).
And to folks in the greater MySQL/tech community and tech co-workers past and present, especially those I have been inspired and helped by: Tracy Gangwer, Selena Deckelmann (Postgres), Amy Rich, Anne Cross, and more (If I have forgotten you, I apologize!).
If you do not know what International Women’s Day is: http://www.internationalwomensday.com/
Start planning your blog posts for Ada Lovelace day now (March 24th, http://findingada.com/ Ada Lovelace Day is an international day of blogging (videologging, podcasting, comic drawing etc.!) to draw attention to the achievements of women in technology and science.)
To that end, I would like to point out all the women currently in science and tech fields that I admire and think are doing great things. I think it would be great if everyone, male or female, made a list like this:
The women that have taught me science/tech along the way:
High School:
Mary Lou Ciavarra (Physics)
Maria Petretti (Pre-Algebra, and Academic Decathlon)
Reneé Fishman (Biology)
Lisa Acquaire (Economics during Academic Decathlon)
College:
Professor Kalpana White (Biology), and in whose fruit fly lab I worked for 2 semesters.
Professor Eve Marder (Introductory Neuroscience)
Though Brandeis does have female faculty in the Computer Science department, I did not manage to have any classes with female Computer Science faculty members.
My current female DBA co-workers at Pythian: Isabel Pinarci (Oracle), Michelle Gutzait (SQL Server), Catherine Chow (Oracle) and Jasmine Wen (Oracle).
And to folks in the greater MySQL/tech community and tech co-workers past and present, especially those I have been inspired and helped by: Tracy Gangwer, Selena Deckelmann (Postgres), Amy Rich, Anne Cross, and more (If I have forgotten you, I apologize!).
Baron makes an excellent point in Why you should ignore MySQL’s key cache hit ratio — ratio is not the same as rate. Furthermore, rate is [often] the important thing to look at.
This is something that, at Pythian, we internalized a long time ago when thinking about MySQL tuning. In fact, mysqltuner 2.0 takes this into account, and the default configuration includes looking at both ratios and rates.
If I told you that your database had a ratio of temporary tables written to disk of 20%, you might think “aha, my database is slow because of a lot of file I/O caused by writing temporary tables to disk!”. However, that 20% ratio may actually mean a rate of 2 per hour — which is most likely not causing excessive I/O.
To get a sense of this concept, and also how mysqltuner works, I will show the lines from the mysqltuner default configuration that deal with temporary tables written to disk. The format is that the fields are separated by three pipes (|||), and the fields are:
label
threshold check
formula
recommendation if “threshold check” is met
Here is the line from the default configuration file that calculates the rate of temporary tables written to disk:
% temp disk tables|||>25|||Created_tmp_disk_tables / (Created_tmp_tables + Created_tmp_disk_tables) * 100|||Too many temporary tables are being written to disk. Increase max_heap_table_size and tmp_table_size.
mysqltuner will parse that as:
if
the value of Created_tmp_disk_tables/(Created_tmp_tables + Created_tmp_disk_tables)*100
>25
then print out the last field.
So that means that a ratio of 25% or more is the threshold. But we found that many clients have a ratio much less than 25%, but still had excessive temporary tables written to disk. So the default configuration also contains a rate calculation of temporary tables written to disk:
temp disk rate|||=~ /second|minute/|||&hr_bytime(Created_tmp_disk_tables/Uptime)|||Too many temporary tables are being written to disk. Increase max_heap_table_size and tmp_table_size.
mysqltuner will parse that as:
if
the value of &hr_bytime(Created_tmp_disk_tables/Uptime)
matches “second” or “minute”
then print out the last field.
The hr_bytime() function in mysqltuner takes a number that is a per-second rate and makes it “human readable” (hence “hr”) by returning the order of magnitude at which the value is >1. For example:
hr_bytime(2) returns “2.0 per second”
hr_bytime(0.2) returns “12.0 per minute”
hr_bytime(0.02) returns “1.2 per minute”
hr_bytime(0.002) returns “7.2 per hour”
hr_bytime(0.0002) returns “17.28 per day”
Certainly, 0.02 looks small, but “12 per minute” is a better metric for a DBA to understand the problem.
Because the configuration file for mysqltuner 2.0 contains the threshold and check, it is fairly simple to change what the threshold is, and to check both rates and ratios. mysqltuner also allows you to output in different formats (currently there’s “pretty” and “csv”, but it’s easy to add a perl subroutine to do something different with the output), which makes it ideal for doing regular tuning checks for what is most important for you.
Pythian uses it on one client to provide weekly reports, which we add to a spreadsheet so that differences are easy to see. (yes, output directly to a database is on the “features we want to add” — mysqltuner is just a perl script, so if anyone in the community wants to add it, they can create a branch and request the feature to be added into the main trunk…it is all on launchpad, at https://launchpad.net/mysqltuner, so community contributions are recommended and encouraged.)
Baron makes an excellent point in Why you should ignore MySQL’s key cache hit ratio — ratio is not the same as rate. Furthermore, rate is [often] the important thing to look at.
This is something that, at Pythian, we internalized a long time ago when thinking about MySQL tuning. In fact, mysqltuner 2.0 takes this into account, and the default configuration includes looking at both ratios and rates.
If I told you that your database had a ratio of temporary tables written to disk of 20%, you might think “aha, my database is slow because of a lot of file I/O caused by writing temporary tables to disk!”. However, that 20% ratio may actually mean a rate of 2 per hour — which is most likely not causing excessive I/O.
To get a sense of this concept, and also how mysqltuner works, I will show the lines from the mysqltuner default configuration that deal with temporary tables written to disk. The format is that the fields are separated by three pipes (|||), and the fields are:
label
threshold check
formula
recommendation if “threshold check” is met
Here is the line from the default configuration file that calculates the rate of temporary tables written to disk:
% temp disk tables|||>25|||Created_tmp_disk_tables / (Created_tmp_tables + Created_tmp_disk_tables) * 100|||Too many temporary tables are being written to disk. Increase max_heap_table_size and tmp_table_size.
mysqltuner will parse that as:
if
the value of Created_tmp_disk_tables/(Created_tmp_tables + Created_tmp_disk_tables)*100
>25
then print out the last field.
So that means that a ratio of 25% or more is the threshold. But we found that many clients have a ratio much less than 25%, but still had excessive temporary tables written to disk. So the default configuration also contains a rate calculation of temporary tables written to disk:
temp disk rate|||=~ /second|minute/|||&hr_bytime(Created_tmp_disk_tables/Uptime)|||Too many temporary tables are being written to disk. Increase max_heap_table_size and tmp_table_size.
mysqltuner will parse that as:
if
the value of &hr_bytime(Created_tmp_disk_tables/Uptime)
matches “second” or “minute”
then print out the last field.
The hr_bytime() function in mysqltuner takes a number that is a per-second rate and makes it “human readable” (hence “hr”) by returning the order of magnitude at which the value is >1. For example:
hr_bytime(2) returns “2.0 per second”
hr_bytime(0.2) returns “12.0 per minute”
hr_bytime(0.02) returns “1.2 per minute”
hr_bytime(0.002) returns “7.2 per hour”
hr_bytime(0.0002) returns “17.28 per day”
Certainly, 0.02 looks small, but “12 per minute” is a better metric for a DBA to understand the problem.
Because the configuration file for mysqltuner 2.0 contains the threshold and check, it is fairly simple to change what the threshold is, and to check both rates and ratios. mysqltuner also allows you to output in different formats (currently there’s “pretty” and “csv”, but it’s easy to add a perl subroutine to do something different with the output), which makes it ideal for doing regular tuning checks for what is most important for you.
Pythian uses it on one client to provide weekly reports, which we add to a spreadsheet so that differences are easy to see. (yes, output directly to a database is on the “features we want to add” — mysqltuner is just a perl script, so if anyone in the community wants to add it, they can create a branch and request the feature to be added into the main trunk…it is all on launchpad, at https://launchpad.net/mysqltuner, so community contributions are recommended and encouraged.)
Applying binary logs to a MySQL instance is not particularly difficult, using the mysqlbinlog command line utility:
$> mysqlbinlog mysql-bin.000003 > 03.sql
$> mysql < 03.sql
Turning off binary logging for a session is not difficult, from the MySQL commandline, if you authenticate as a user with the SUPER privilege:
mysql> SET SESSION sql_log_bin=0;
However, sometimes you want to apply binary logs to a MySQL instance, without having those changes applied to the binary logs themselves. One option is to restart the server binary logging disabled, and after the load is finished, restart the server with binary logging re-enabled. This is not always possible nor desirable, so there’s a better way, that works in at least versions 4.1 and up:
The mysqlbinlog utility has the --disable-log-bin option. All the option does is add the SET SESSION sql_log_bin=0; statement to the beginning of the output, but it is certainly much better than restarting the server twice!
Here’s the manual page for the --disable-log-bin option of mysqlbinlog: http://dev.mysql.com/doc/refman/5.1/en/mysqlbinlog.html#option_mysqlbinlog_disable-log-bin
Applying binary logs to a MySQL instance is not particularly difficult, using the mysqlbinlog command line utility:
$> mysqlbinlog mysql-bin.000003 > 03.sql
$> mysql < 03.sql
Turning off binary logging for a session is not difficult, from the MySQL commandline, if you authenticate as a user with the SUPER privilege:
mysql> SET SESSION sql_log_bin=0;
However, sometimes you want to apply binary logs to a MySQL instance, without having those changes applied to the binary logs themselves. One option is to restart the server binary logging disabled, and after the load is finished, restart the server with binary logging re-enabled. This is not always possible nor desirable, so there’s a better way, that works in at least versions 4.1 and up:
The mysqlbinlog utility has the --disable-log-bin option. All the option does is add the SET SESSION sql_log_bin=0; statement to the beginning of the output, but it is certainly much better than restarting the server twice!
Here’s the manual page for the --disable-log-bin option of mysqlbinlog: http://dev.mysql.com/doc/refman/5.1/en/mysqlbinlog.html#option_mysqlbinlog_disable-log-bin
Just the facts:
What: MySQL user community dinner
Who: me, you, and many MySQL community members
When: Monday, April 12th – Meet at 6:30 at the Hyatt Santa Clara or at 7 pm at the restaurant
Where: Pedro’s Restaurant and Cantina – 3935 Freedom Circle, Santa Clara, CA 95054
How: Comment on this blog post to add your name to the list of probable attendees
I was sad that last year there was no community dinner, and I missed the one the year before when Jonathan Schwartz and Rich Green made an appearance. This year I am determined not to miss it, and so I am calling for a community (pay-your-own-way) dinner on Monday, April 12th, at Pedro’s – a Mexican restaurant that has vegetarian and vegan options. I think Monday is a better time because many folks arrive Sunday evening, or even Monday morning (there are tutorials on Monday, but not everyone attends).
Pedro’s can handle large groups of people, but we would like to have a vague idea of how many people are attending — while you are not required to RSVP, we would like to make an accurate reservation at Pedro’s….In 2008, there was a wiki page with a list of attendees, and I was disappointed because there were so many people on that list I wanted to see.
Meet us at 6:30 pm on Monday in the lobby of the Hyatt Santa Clara, or at 7 pm at Pedro’s. If you want to come later, just show up at Pedro’s whenever you can.
Since commenting on this blog does not require registration (as the wiki does), I invite folks to comment on this blog post and I’ll add you to the list of attendees:
Sheeri K. Cabral (The Pythian Group)
Paul Vallee (The Pythian Group)
Rob Hamel (The Pythian Group)
Giuseppe Maxia (Sun)
Brian Aker (Drizzle)
Konstantin Osipov (Sun)
Mark Callaghan (Facebook) (will arrive later)
Wagner Bianchi (EAC Software, Brazil)
Bill Karwin (Karwin Software Solutions)
Maxim Volkov (OpenCandy)
Brian Moon (DealNews) – note: Monday Apr 12th is Brian’s birthday!
Rob Peck (DealNews)
Arjen Lentz (OpenQuery)
Vadim Tkachenko (Percona)
Rohit Nadhani (WebYog)
Just the facts:
What: MySQL user community dinner
Who: me, you, and many MySQL community members
When: Monday, April 12th – Meet at 6:30 at the Hyatt Santa Clara or at 7 pm at the restaurant
Where: Pedro’s Restaurant and Cantina – 3935 Freedom Circle, Santa Clara, CA 95054
How: Comment on this blog post to add your name to the list of probable attendees
I was sad that last year there was no community dinner, and I missed the one the year before when Jonathan Schwartz and Rich Green made an appearance. This year I am determined not to miss it, and so I am calling for a community (pay-your-own-way) dinner on Monday, April 12th, at Pedro’s – a Mexican restaurant that has vegetarian and vegan options. I think Monday is a better time because many folks arrive Sunday evening, or even Monday morning (there are tutorials on Monday, but not everyone attends).
Pedro’s can handle large groups of people, but we would like to have a vague idea of how many people are attending — while you are not required to RSVP, we would like to make an accurate reservation at Pedro’s….In 2008, there was a wiki page with a list of attendees, and I was disappointed because there were so many people on that list I wanted to see.
Meet us at 6:30 pm on Monday in the lobby of the Hyatt Santa Clara, or at 7 pm at Pedro’s. If you want to come later, just show up at Pedro’s whenever you can.
Since commenting on this blog does not require registration (as the wiki does), I invite folks to comment on this blog post and I’ll add you to the list of attendees:
Sheeri K. Cabral (The Pythian Group)
Paul Vallee (The Pythian Group)
Rob Hamel (The Pythian Group)
Giuseppe Maxia (Sun)
Brian Aker (Drizzle)
Konstantin Osipov (Sun)
Mark Callaghan (Facebook) (will arrive later)
Wagner Bianchi (EAC Software, Brazil)
Bill Karwin (Karwin Software Solutions)
Maxim Volkov (OpenCandy)
Brian Moon (DealNews) – note: Monday Apr 12th is Brian’s birthday!
Rob Peck (DealNews)
Arjen Lentz (OpenQuery)
Vadim Tkachenko (Percona)
Rohit Nadhani (WebYog)
There are those that are very adamant about letting people know that using INFORMATION_SCHEMA can crash your database. For example, in making changes to many tables at once Baron writes:
“querying the INFORMATION_SCHEMA database on MySQL can completely lock a busy server for a long time. It can even crash it. It is very dangerous.”
Though Baron is telling the truth here, he left out one extremely important piece of information: you can actually figure out how dangerous your INFORMATION_SCHEMA query will be, ahead of time, using EXPLAIN.
In MySQL 5.1.21 and higher, not only were optimizations made to the INFORMATION_SCHEMA, but new values were added so that EXPLAIN had better visibility into what MySQL is actually doing. As per http://dev.mysql.com/doc/refman/5.1/en/information-schema-optimization.html there are 6 new “Extra” values for EXPLAIN that are used only for INFORMATION_SCHEMA queries.
The first 2 “Extra” values for EXPLAIN are mostly self-explanatory:
Scanned 1 database – Only one database directory needs to be scanned.
Scanned all databases – All database directories are scanned. This is more dangerous than only scanning one database.
Note that there is no middle ground — there is no optimization to only scan 2 databases; either all database directories are scanned, or only one is. If your query spans more than one database, then all database directories are scanned. Note that this
SHOW statements are less dangerous than using INFORMATION_SCHEMA because they only use one database at a time. If you have an INFORMATION_SCHEMA query that produces an “Extra” value of “Scanned 1 database”, it is just as safe as a SHOW statement.
The optimizations went even further, though. From the most “dangerous” — ie, resource intensive — to the least, here are the other 4 “Extra” values introduced in MySQL 5.1.21 (which, for the record, came out in August 2007, so it is a feature that has been around for 2.5 years at this point):
Open_full_table
Open_trigger_only
Open_frm_only
Skip_open_table
A bit more explanation, and some examples:
Open_full_table – Needs to open all the metadata, including the tables format file (.frm) and data/index files such as .MYD and .MYI. The previously linked to manual page about the optimization includes which information will show each “Extra” type — for example, the AUTO_INCREMENT and DATA_LENGTH fields of the TABLES table require opening all the metadata.
mysql> EXPLAIN SELECT TABLE_SCHEMA,TABLE_NAME,AUTO_INCREMENT FROM TABLES\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TABLES
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Open_full_table; Scanned all databases
1 row in set (0.00 sec)
Let’s see an example that only scans 1 database:
mysql> EXPLAIN TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA='test'\G
ERROR 1109 (42S02): Unknown table 'TABLE_NAME' in information_schema
mysql> EXPLAIN SELECT TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA='test'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TABLES
type: ALL
possible_keys: NULL
key: TABLE_SCHEMA
key_len: NULL
ref: NULL
rows: NULL
Extra: Using where; Open_full_table; Scanned 1 database
1 row in set (0.00 sec)
Note that “Scanned all databases” will apply if there is any way there could be more than one database. For example, on my test server, only the ‘test’ and ’sakila’ databases exist (other than ‘mysql’ and ‘INFORMATION_SCHEMA’ of course) and yet when I do
EXPLAIN SELECT TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA LIKE 'test%'\G
I still get “Scanned all databases”. So be careful.
One of the basic pieces of advice I see to optimize queries can be applied to queries on the INFORMATION_SCHEMA — Do not use SELECT * unless you actually want to get every single piece of information. In the case of INFORMATION_SCHEMA, optimizing your queries can mean the difference between the server crashing and the server staying up.
Open_trigger_only – Only the .TRG file needs to be opened. Interestingly enough, this does not seem to have an example that applies. The manual page says that the TRIGGERS table uses Open_full_table for all fields. When I tested it, though, I did not get anything in the “Extra” field at all — not “Open_trigger_only” and not even “Open_full_table”:
mysql> select @@version;
+---------------------+
| @@version |
+---------------------+
| 5.1.37-1ubuntu5-log |
+---------------------+
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM TRIGGERS\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TRIGGERS
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
1 row in set (0.00 sec)
Open_frm_only – Only the format file (.frm) of the table needs to be open. Again, check the manual page for the fields that can use this optimization — fields such as CREATE_OPTIONS and ENGINE in the TABLES table do, for example.
Skip_open_table – This is the last new “Extra” feature, and it is the best. This optimization type means that no files need to be opened. The database directories are scanned and information can be obtained — mostly the table name, so when querying only the TABLE_NAME and TABLE_SCHEMA fields from the TABLES table, your query is safe.
So instead of putting your head in the sand and never using the great tool that is the INFORMATION_SCHEMA, first EXPLAIN your query to see if it will work or not.
(Note, if you are still on MySQL 5.0, what are you waiting for? The upgrade to MySQL 5.1 is relatively painless, and Pythian has a comprehensive checklist for how to upgrade while keeping your sanity).
There are those that are very adamant about letting people know that using INFORMATION_SCHEMA can crash your database. For example, in making changes to many tables at once Baron writes:
“querying the INFORMATION_SCHEMA database on MySQL can completely lock a busy server for a long time. It can even crash it. It is very dangerous.”
Though Baron is telling the truth here, he left out one extremely important piece of information: you can actually figure out how dangerous your INFORMATION_SCHEMA query will be, ahead of time, using EXPLAIN.
In MySQL 5.1.21 and higher, not only were optimizations made to the INFORMATION_SCHEMA, but new values were added so that EXPLAIN had better visibility into what MySQL is actually doing. As per http://dev.mysql.com/doc/refman/5.1/en/information-schema-optimization.html there are 6 new “Extra” values for EXPLAIN that are used only for INFORMATION_SCHEMA queries.
The first 2 “Extra” values for EXPLAIN are mostly self-explanatory:
Scanned 1 database – Only one database directory needs to be scanned.
Scanned all databases – All database directories are scanned. This is more dangerous than only scanning one database.
Note that there is no middle ground — there is no optimization to only scan 2 databases; either all database directories are scanned, or only one is. If your query spans more than one database, then all database directories are scanned. Note that this
SHOW statements are less dangerous than using INFORMATION_SCHEMA because they only use one database at a time. If you have an INFORMATION_SCHEMA query that produces an “Extra” value of “Scanned 1 database”, it is just as safe as a SHOW statement.
The optimizations went even further, though. From the most “dangerous” — ie, resource intensive — to the least, here are the other 4 “Extra” values introduced in MySQL 5.1.21 (which, for the record, came out in August 2007, so it is a feature that has been around for 2.5 years at this point):
Open_full_table
Open_trigger_only
Open_frm_only
Skip_open_table
A bit more explanation, and some examples:
Open_full_table – Needs to open all the metadata, including the tables format file (.frm) and data/index files such as .MYD and .MYI. The previously linked to manual page about the optimization includes which information will show each “Extra” type — for example, the AUTO_INCREMENT and DATA_LENGTH fields of the TABLES table require opening all the metadata.
mysql> EXPLAIN SELECT TABLE_SCHEMA,TABLE_NAME,AUTO_INCREMENT FROM TABLES\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TABLES
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Open_full_table; Scanned all databases
1 row in set (0.00 sec)
Let’s see an example that only scans 1 database:
mysql> EXPLAIN TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA='test'\G
ERROR 1109 (42S02): Unknown table 'TABLE_NAME' in information_schema
mysql> EXPLAIN SELECT TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA='test'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TABLES
type: ALL
possible_keys: NULL
key: TABLE_SCHEMA
key_len: NULL
ref: NULL
rows: NULL
Extra: Using where; Open_full_table; Scanned 1 database
1 row in set (0.00 sec)
Note that “Scanned all databases” will apply if there is any way there could be more than one database. For example, on my test server, only the ‘test’ and ’sakila’ databases exist (other than ‘mysql’ and ‘INFORMATION_SCHEMA’ of course) and yet when I do
EXPLAIN SELECT TABLE_NAME,AUTO_INCREMENT FROM TABLES WHERE TABLE_SCHEMA LIKE 'test%'\G
I still get “Scanned all databases”. So be careful.
One of the basic pieces of advice I see to optimize queries can be applied to queries on the INFORMATION_SCHEMA — Do not use SELECT * unless you actually want to get every single piece of information. In the case of INFORMATION_SCHEMA, optimizing your queries can mean the difference between the server crashing and the server staying up.
Open_trigger_only – Only the .TRG file needs to be opened. Interestingly enough, this does not seem to have an example that applies. The manual page says that the TRIGGERS table uses Open_full_table for all fields. When I tested it, though, I did not get anything in the “Extra” field at all — not “Open_trigger_only” and not even “Open_full_table”:
mysql> select @@version;
+---------------------+
| @@version |
+---------------------+
| 5.1.37-1ubuntu5-log |
+---------------------+
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM TRIGGERS\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: TRIGGERS
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
1 row in set (0.00 sec)
Open_frm_only – Only the format file (.frm) of the table needs to be open. Again, check the manual page for the fields that can use this optimization — fields such as CREATE_OPTIONS and ENGINE in the TABLES table do, for example.
Skip_open_table – This is the last new “Extra” feature, and it is the best. This optimization type means that no files need to be opened. The database directories are scanned and information can be obtained — mostly the table name, so when querying only the TABLE_NAME and TABLE_SCHEMA fields from the TABLES table, your query is safe.
So instead of putting your head in the sand and never using the great tool that is the INFORMATION_SCHEMA, first EXPLAIN your query to see if it will work or not.
(Note, if you are still on MySQL 5.0, what are you waiting for? The upgrade to MySQL 5.1 is relatively painless, and Pythian has a comprehensive checklist for how to upgrade while keeping your sanity).
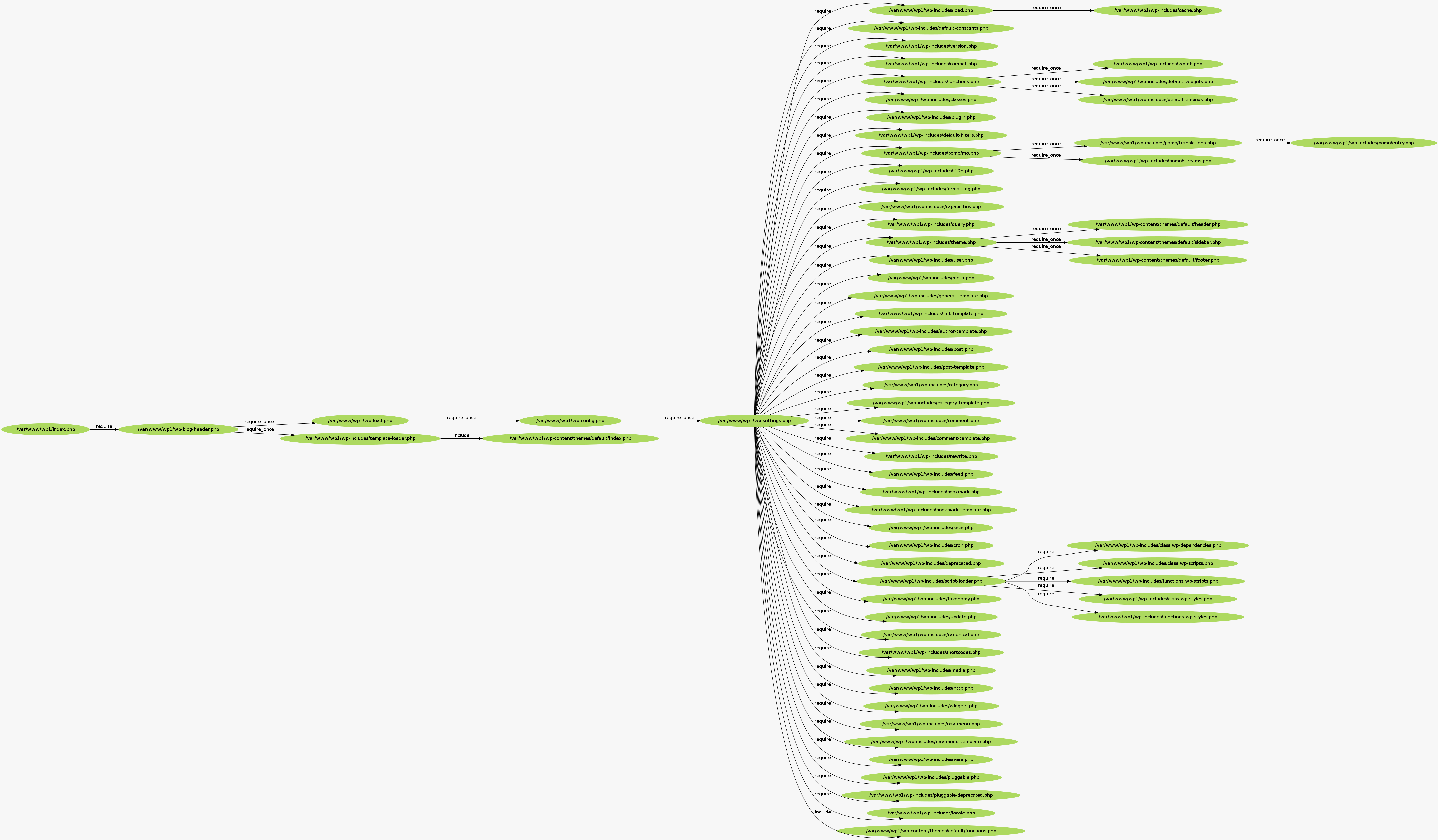{kind=link}
{kind=link}